Разработка ядра информационной системы. Часть 2.
Вся публикация: Исторический контекст | Часть 1 | Часть 2 | Часть 3
В предыдущей части статьи мы определили основные требования к нашей реализации и создали в первом приближении концептуальную модель данных ядра АИС. А сейчас рассмотрим пример реализации концепции на базе СУБД PostgreSQL (по-русски читается как «постгрес»).
Какие же качества привлекли нас в этой СУБД?
- Зрелость продукта, историю создания которого можно прочитать, например, в википедии.
- Наличие открытой и бесплатной лицензии, поддержка со стороны многочисленного (десятки тысяч) сообщества.
- Развитый встроенный процедурный язык (PL/pgSQL) и средства расширения.
- Переносимость. Вложив труд в разработку, можно использовать результаты на разных операционных системах. Данная особенность еще более интересна вследствие увеличивающейся доли проектов на Linux-платформе.
Так, даже будучи давним пользователем MS SQL Server, автор тем не менее считает привязку к платформе Windows серьезным ограничением для разработки обобщенного ядра АИС.
Оформление
Сначала немного о стиле кодирования. Для идентификаторов — имен таблиц, полей, функций и проч. — будем использовать смешанный регистр символов, так называемый верблюжий (CamelCaps), например ObjectVersion. Хотя PostgreSQL и нечувствителен к регистру: и ObjectVersion, и objectversion он воспринимает как один и тот же идентификатор, но человек такой код читает лучше, чем написанный в одном регистре. Мы также воспользуемся пространствами имен, реализованными в СУБД в виде схем. Создавать структуры и функции будем в пространстве (схеме) с характерным названием Core. Идентификаторы могут иметь префиксы. Для пользовательских типов данных (доменов) применим префикс «T» (Type), для таблиц классов — «C» (Class), для таблиц локализованных атрибутов (полей) классов — «L» (Loca-lized data). Более подробные примеры имеются в исходных текстах, но о них позже.
Логика и структура системы
От концептуальной схемы БД перейдем к логической (физической, в терминах CASE-средств, например, PowerDesigner или ERwin).
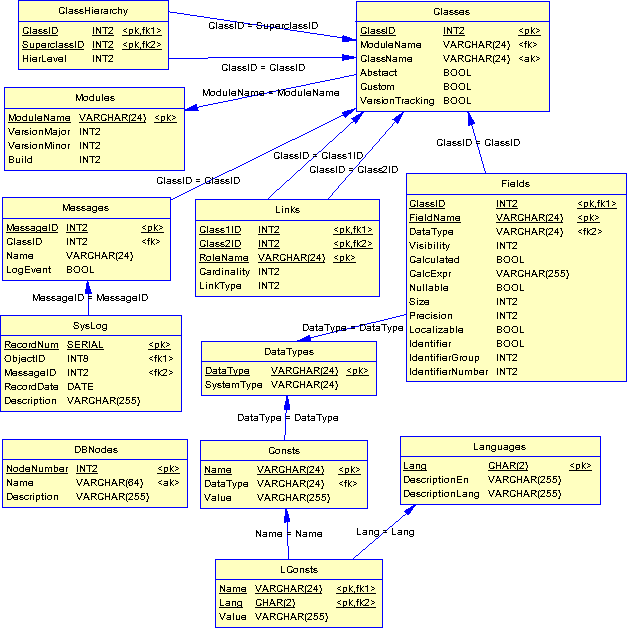
Рис.1. Структура ядра и метаданные
В ключевой таблице Core.Classes, как понятно из названия, хранятся описания классов объектов системы. Описание состоит из имени класса (ClassName), имени содержащего данный класс модуля (ModuleName), признаков абстрактного (Abstract) и определяемого программистом настраиваемого (Custom) класса. Имя класса, как и все другие системные имена, относится к типу TSystemName и ограничено 24 символами. Модуль системы — это единица группировки классов, соответствующая некоторой подсистеме с законченной функциональностью. Так, модулем является ядро. Если вы создадите на базе ядра функциональность учета товаров, то соответствующие классы сможете объединить в качестве модуля «Склад» и т.д. Признак настраиваемого класса означает, что система не генерирует код по метаданным и написать его должен сам разработчик. Первичным ключом считается автоматически генерируемый целочисленный ClassID. Его введение связано исключительно с вопросами эффективности, о чем будет сказано чуть ниже.
Иерархия классов хранится в таблице Core.ClassHierarchy. Для ее создания используется метод подмножеств, см. Проектирование баз данных: иерархические структуры.
В таблице Core.Fields содержатся описания атрибутов (полей) классов.
Смысл большинства атрибутов понятен из названий. Остановимся на некоторых из них. Признак Calculated означает вычислимый атрибут, а CalcExpr — выражение для его вычисления. При генерации проекций система определит соответствующее поле как выражение AS <имя атрибута>. Признак Localizable включает локализацию атрибутов класса: генерируется отдельная таблица с префиксом «L» и названием имени класса, где собираются все локализованные атрибуты класса. Ключом такой таблицы будет Object ID и двусимвольный код языка по ISO. Соответствующий язык (RU, EN, FR…) приведен в таблице Languages. Наконец, признак идентификатора означает, что поле представляет собой логический идентификатор, т.е. по нему легко однозначно найти нужный объект.
Например, это может быть код товара, исходящий номер документа, табельный номер сотрудника и т.д. В отдельных случаях идентификатор бывает составным (состоит из нескольких атрибутов, например, из номера и серии паспорта). В этом случае определяется номер группы и порядковый номер следования атрибута в группе. Физически идентификатор будет соответствовать альтернативному ключу таблицы БД.
В таблице Core.Links описаны связи между классами с именами Class1Name и Class2Name. Мощность связи (Cardinality) принимает значения «один к одному», «один ко многим» и «многие ко многим». Тип связи (LinkType) может быть агрегацией (простая связь: обязательная или необязательная) или композицией (ключевая связь: связанный объект не должен существовать без родительского).
В таблице Core.Messages определены сообщения, которые допускается посылать объекту данного класса (с учетом иерархии наследования). Для каждого сообщения программист может создать любое число методов (функций) обработчиков, имеющих сигнатуру <Имя класса>_<Имя сообщения>_<Имя обработчика>. Отправка сообщения объекту инициирует в ядре вызов всех обработчиков в контексте транзакции с обработкой возможных ошибок и последующим откатом. Существует несколько системных сообщений уровня базового класса Object с зарезервированными именами, например Update или Delete, которые инициируются при работе с проекциями. При этом ядро вызывает обработчики для всех объектов, измененных или удаленных в проекции.
В журнале регистрации событий (аудита) Core.SysLog хранится протокол всех сообщений, отправленных объектам. По нему можно восстановить последовательность действий пользователя.
Сама история изменений атрибутов объекта будет содержаться в соответствующей таблице с префиксом «H» (History), если для класса включена версионность.
В таблице Core.Consts собраны именованные константы. Например, можно хранить число 3.1415926 под именем PI. Другое важное применение констант — локализованные сообщения, выдаваемые сервером при ошибке или извещении о событии.
В таблице Core.DBNodes содержатся внутренние номера баз данных, на которых установлена система. Имя и номер БД должны быть уникальны в пределах всей системы, а не только сервера. Номер БД используется для генерации уникальных идентификаторов объектов и, таким образом, обеспечивает бесконфликтный обмен данными при использовании репликации.
Альтернатива — применение идентификаторов типа GUID. Правда, поскольку такой вариант ориентирован на машинную обработку, то человеку, и прежде всего разработчику, трудно выполнять анализ данных на уровне таблиц.
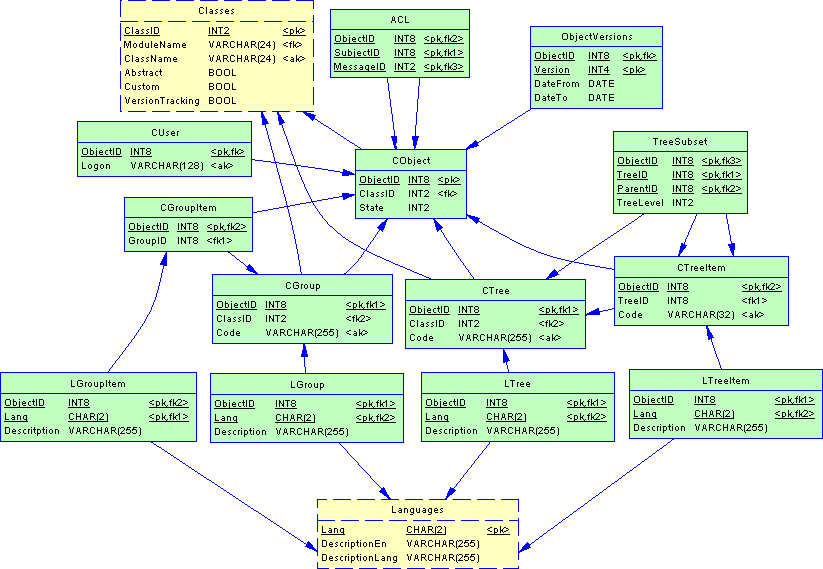
Рис. 2. Базовые объекты и сервисы
Ключевой таблицей является Core.CObject. Целочисленный уникальный идентификатор имеет 64-разрядный тип INT8 (синоним bigint), позволяющий хранить значения в диапазоне от –263 (–9223372036854775808) до 263–1 (9223372036854775807).
Три старших разряда мы используем в качестве номера БД (узла), остальные будут отведены под автоматически генерируемый на уровне БД порядковый номер объекта. Например, идентификатор 1230000000000004567 обозначает в системе объект 4567, созданный в БД с номером 123. Три разряда, выделенные под номер БД, ограничивают количество узлов в системе числом 999, но это непринципиально: можно просто модифицировать функцию генерации идентификатора Core. Object_NewID(). Атрибут ClassID содержит ссылку на класс объекта в таблице Core.Classes. Очевидно, что вместо использования ClassName необходимо ввести в таблицу классов дополнительный ключ: при наличии в системе 100 млн. объектов размер таблицы уменьшится примерно на 100 млн × (24 – 2) = 2,15 Гбайт. Третий атрибут, State, служит для хранения состояния объекта. Предполагаемое использование: 0 — черновик, 1 — активен, 2 — удален.
В служебной таблице Core.Object Versions приведена информация об изменениях тех объектов, для классов которых в системе была включена версионность. Мы используем здесь стандартную схему «Хранение номера периода», подробно описанную ранее, см. Проектирование баз данных: хронологические данные. Все классы с включенной версионностью будут хранить свои атрибуты в таблицах, ссылающихся не только на ObjectID, но и на номер версии. Ключом такой таблицы будет пара (ObjectID, Version).
Еще одна важная таблица — Core.ACL, составляющая основу подсистемы безопасности.
Она определяет, есть ли доступ типа MessageID к объекту ObjectID со стороны субъекта SubjectID. Объект MessageID может ссылаться на сообщения любых типов, включая вводимые разработчиком. Изначально на уровне ядра имеется несколько типов сообщений, присущих базовому классу Object: READ (доступ на чтение, определяет видимость объекта в проекции), CREATE (доступ связан с классом, а не объектом), WRITE, DELETE, UNDELETE, ACTIVATE (перевод в активное состояние).
В качестве субъекта доступа может выступать пользователь системы или рабочая (ролевая) группа. В таблице Core.CUser пользователь однозначно определяется своим именем регистрации (Logon) в системе безопасности PostgreSQL. В каждом открытом соединении с СУБД поддерживается функция session_user(), возвращающая имя пользователя, по которому мы находим в таблице Core. CUser соответствующий ему ObjectID и определяем права доступа в Core. ACL по условию соединения ACL.SubjectID = CUser.ObjectID.
Группировки
В состав ядра также войдут сервисы группировок объектов: линейных и древовидных (иерархических). Базовые классы для группировок имеют имена Group и Tree. Для их хранения используется несколько таблиц. Core.CGroup содержит сами группы, а атрибут Code предназначен для хранения уникального внеязыкового кода группы. Например, код группы студентов (84005), код линейного классификатора согласно отраслевому или государственному стандарту (ОК 003-99), внутрифирменный код группирования чего-либо (КЛ12345). Атрибут ClassID ограничивает класс объектов, которые могут входить в данную группу. Элементы группы находятся в Core.CGroupItem.
Группы и элементы могут иметь многоязычные описания, хранящиеся в таблицах Core.LGroup и Core.LGroupItem соответственно.
С иерархиями дела обстоят аналогично, за исключением дополнительной таблицы Core.TreeSubset, содержащей структуру связей в дереве. Здесь мы также используем метод подмножеств, описанный ранее.
Предварительный итог
Мы рассмотрели общую логику и структуру системы на уровне реализации. Теперь дело за разработкой конкретного примера. Для его описания в рамках объектного подхода можно воспользоваться нотацией UML (Unified Modeling Language — унифицированный язык моделирования).
Реализация примера будет обсуждаться в третьей части.
Сергей Тарасов, май 2007.
Статья также опубликована в журнале "Мир ПК" №7-2007.
PostgreSQL: передача сообщений сервера БД клиенту
СУБД PostgreSQL может передавать клиенту сообщения в асинхронном режиме. Для этого в языке предусмотрены операторы RAISE NOTICE и RAISE EXCEPTION. Аналогичная функциональность в Microsoft SQL Server и Sybase ASE реализована операторами PRINT и RAISERROR.
В чем же преимущества такого механизма?
Предположим, клиент вызывает метод объекта. В рассматриваемой нами реализации это будет вызов хранимой процедуры/функции. Если по ходу выполнения возникает логическая ошибка, например, при расходе товара получилось отрицательное количество, то метод выполняет необходимые действия по отмене операции и посредством RAISE EXCEPTION передает сообщение об ошибке клиенту, прерывая работу хранимой функции. Однако может возникнуть ситуация, когда ошибки нет, но нужно передать клиенту дополнительную информацию, не прерывая ход процедуры, например, если при расходе товара остается последний экземпляр. В этом случае поможет RAISE NOTICE.
В обоих случаях клиент должен уметь перехватывать сообщения сервера. Конечно, это будет программирование на довольно низком уровне, но оно, к счастью, уже выполнено разработчиками многочисленных компонентов доступа к СУБД. Так, для Delphi существует пакет PostgresDAC, в составе которого компонент TPSQLNotify занимается обработкой поступающих от СУБД сообщений. В открытом и бесплатном пакете ZeosDBO также предусмотрен перехват сообщений на уровне компонента соединения. В составе Microsoft ADO (ActiveX Data Objects) компонент доступа Connection имеет событие InfoMessage, не являющееся полноценным обработчиком, поскольку обладает существенными ограничениями. Для использования механизма придется спускаться на уровень OLE DB. В среде. NET компонент NpgsqlConnection имеет событие Notification для полноценной обработки сообщений как в синхронном, так и в асинхронном режиме.
Интересная возможность применения сообщений — реализация на их основе простых протоколов управления тонкими или «умными» (smart) клиентами. Приведу простой пример: тонкий клиент вызывает метод печати объекта, причем он не знает, каким именно способом она реализована для данного класса объектов: встроенный генератор отчетов, внешний отчет Crystal Report, экспорт документа в MS Word, экспорт в HTML. Отдельные из перечисленных методов клиент может и вовсе не поддерживать. Простейший протокол выглядит так:
- Клиент указывает серверу выполнить метод «Печать» для документа с идентификатором «12345».
- Сервер заполняет буферные таблицы отчета, определяет, каким способом печатать документы данного типа, посылает сообщение «Данные готовы, запусти экспорт и печать в MS Word».
Поскольку количество сообщений от сервера может быть больше одного, то возможна реализация выдачи серии команд управления «умному» клиенту.