Разработка ядра информационной системы. Часть 1.
Вся публикация: Исторический контекст | Часть 1 | Часть 2 | Часть 3
Вступление
Название статьи содержит два термина, требующих пояснений до того, как мы перейдем к изложению. Автору нравятся лаконичные формулировки ГОСТ.
Автоматизированная система — система, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующая информационную технологию выполнения установленных функций (ГОСТ 34.003—90 п. 1.1).
Информационная система — система, предназначенная для хранения, обработки, поиска, распространения, передачи и предоставления информации (ГОСТ 7.0—99 п. 3.1.30).
Выражаясь еще более кратко, автоматизированная информационная система (АИС) — это люди, использующие информационную технологию средствами автоматизации.
В первой части мы коротко, насколько позволяет формат статьи, рассмотрим требования к АИС, основные концепции и проектные решения. Во второй части остановимся на вопросах и примерах реализации ядра системы.
Обращаю ваше внимание, что речь в статье идет не о теоретических изысканиях автора, данный проект фактически «живой», поэтому по ходу изложения возможно внесение непринципиальных изменений. Предыдущая реализация подобной архитектуры на базе MS SQL Server 2000 показала свою жизнеспособность и преимущества, а в качестве развития проекта предполагается не только создание более широкой функциональности, но и перенос ядра на открытую свободную платформу — СУБД PostgreSQL. Для проекта будет открыт вики (wiki — открытая система веб-публикаций), где заинтересованные коллеги смогут внести свои коррективы в ход реализации.
Разработка «от ядра»
Под ядром АИС будем понимать базовый функционал, набор служб, не зависящий от области применения системы.
Пользуясь определениями АИС (и опытом их разработки), перечислим основные требования к ядру системы.
- Промышленный стандарт реляционной СУБД, имеющий службы хранения, поиска, передачи информации.
- Поддержка объектно-ориентированного подхода (ООП) (фактически еще один промышленный стандарт), обеспечивающего обработку данных и реализацию прикладной логики.
- Подсистема метаданных — всегда актуальное описание информационной модели.
- Подсистема версионности информации, предоставляющая возможности от простой функции логического удаления по принципу мусорной корзины до хранения всей последовательности изменения информации.
- Подсистема безопасности, обеспечивающая управление доступом персонала к информации и ведение аудита.
- Подсистема локализации данных. Персонал может быть интернациональным, а информация — представлена на многих языках. Отмечу, речь идет именно о данных, а не о локализации интерфейса: это две разные задачи, имеющие пересечения.
- Подсистема группировки данных, позволяющая объединять информацию и ранжировать ее по разным признакам, включая иерархии.
Видимо, можно добавить и другие пункты, но остановимся пока на этих семи.
Если взглянуть на структуру АИС, представленную в виде матрицы технологических слоев и уровней прикладных абстракций, то мы будем создавать функционал ячеек 1, 2 и частично 4, 5. Например, пункт 7 из вышеперечисленных относится к системным службам каталогизации.
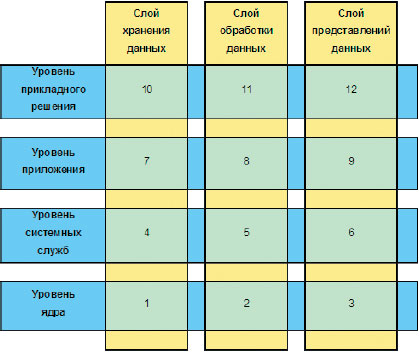
Рис.1. Матрица АИС в слоях и уровнях
Принцип разработки «от ядра» подразумевает создание прикладных модулей на основе этого ядра. Модули используют сервисы ядра, а оно в свою очередь может управлять модулями в соответствии с принятыми соглашениями об интерфейсах. В этом случае создается среда и каркас (framework), используя которые разработчик может сосредоточиться исключительно на прикладных задачах. Система растет уровнями, хотя равномерность роста не гарантирована и, более того, не является обязательной. Например, на базе ядра и набора системных сервисов вы можете создать приложения «Учет кадров», «Расчет зарплаты», «Поиск персонала», объединив их в решение «Управление персоналом», при этом связанные решения и приложения («Бухгалтерия», «Управление проектами» и т.п.) могут быть интегрированы из других систем.
Скрещиваем ежа и ужа
Речь идет о пунктах 1 и 2 нашей семерки требований. Реляционная и объектная модели ортогональны, поэтому «скрещивание» всегда будет состоять из проекции одной модели на другую. Скрещивать можно на двух уровнях:
- самой СУБД, используя развитый механизм проекций (view) и хранимых процедур;
- клиента СУБД (клиентом может быть и сервер приложений). Для этого случая имеется ряд готовых решений объектно-реляционной проекции — ОРП (англоязычный термин ORM — object relational mapping), таких как ECO (Bold), Hibernate (NHibernate), JDO, XPO, Vanatec и др.
Не забудем, что «скрещивание» предполагает и реализацию прикладной логики (бизнес-логики), т.е. той самой обработки данных. В первом случае обработка проходит в адресном пространстве сервера БД. Во втором объекты существуют в адресном пространстве клиента, а СУБД используется в качестве пассивного хранилища. Достоинства и недостатки обоих решений известны, я приведу наиболее очевидные из них.
- Высокие накладные расходы (overhead) для манипуляций с объектами вне адресного пространства СУБД во втором случае. Например, чтобы сложить два поля (свойства) целого типа двух разных объектов и сохранить их в поле третьего, требуется извлекать значения, передавать по сети клиенту, там складывать, возвращать обратно и сохранять (технологические расходы на упаковку/распаковку и межпроцессную передачу). В первом случае все операции происходят локально (in-process).
- Проблема интероперабельности - невозможность разделять прикладную логику между разными приложениями, работающими с одной БД. Действительно, если для доступа к БД имеется множество промышленных стандартов API (Application Programming Interface — интерфейс прикладного программирования), таких как ODBC, JDBC, OLE DB, ADO, ADO.NET и др., то в случае 2 ваш слой объектов доступа будет уникальным и на уровне API, и на уровне среды исполнения. Например, созданный с помощью NHibernate слой фактически недоступен для Win32, PHP и Java-приложений, тогда как доступ к таблицам и хранимым процедурам можно осуществить практически из любой среды разработки и даже стороннего приложения (Microsoft Excel).
- Проблемы оптимизации и тонкой настройки взаимодействия с БД. В общем случае использования СУБД в качестве пассивного хранилища вы не работаете с БД напрямую, за взаимодействие отвечает ваш «проектор». Даже готовые ОРП имеют много узких мест, которые придется обходить.
- Переносимость между СУБД. Это тот случай, когда вариант 2 имеет преимущества. В первом мы привязаны к реализации логики на конкретной СУБД и перенос фактически означает переписывание большой части кода для новой платформы.
- Управление процессами в многопользовательской среде, диспетчеризация, обмен сообщениями. В первом случае мы используем фактически готовые механизмы, предоставляемые самой СУБД, но изменить их при необходимости практически невозможно.
- Проблемы балансировки нагрузки. Разными путями, но с успехом решаются в обоих случаях.
Проблемы 1—3 частично решаются в архитектуре с выделенным сервером (серверами) приложения: доступ к данным и логика разделяются на уровне сервера.Реализация подобной архитектуры является нетривиальной технической и неочевидной экономической задачей: возникает необходимость в системных разработчиках, усложняется система, повышается стоимость владения.
В рамках статьи мы будем рассматривать только первый вариант: реализация логики, в том числе и уровня ядра, средствами самой СУБД. Выбор в пользу первого варианта представляется разумным во многих случаях, когда приложение ориентировано на обработку постоянно хранимых данных, а не потоковой или пакетной информации. Это первое решение, ограничивающее будущую область применения. В дальнейшем будет принято еще несколько подобных решений, составляющих основу будущего ядра АИС.
Если вернуться к приведенной выше матрице, становится понятно, почему ячейки 3 и 6 остаются вне рассмотрения: мы выбрали вариант с реализацией открытого интерфейса доступа к данным на основе имеющихся промышленных стандартов, уровень ядра слоя представлений будет основан на этих стандартах соответственно нам не потребуется создание собственного интерфейса (API).
Основные принципы
Нельзя объять необъятное, поэтому вначале мы сформулируем основные проектные решения, одновременно являющиеся и ограничениями.
Объектная модель. Используется схема обобщения (наследования) с общим для всех абстрактным предком (суперклассом) Object. Любой класс в системе является прямым или дальним потомком (подклассом) класса Object. Множественное наследование не поддерживается. По умолчанию используется схема отображения 2 (см. Приложение. Методы отображения: основные понятия и термины) «класс — таблица», т.е. каждый класс отображается на новую таблицу, а связь 1:1 с таблицей суперкласса (предка) осуществляется по ключу-идентификатору ObjectID; атрибуты суперкласса не переносятся в подкласс, за исключением ключа. На самом деле метод отображения на таблицы на данном этапе не так важен, поскольку снаружи классы будут видны только как проекции.
Проекции (view) автоматически генерируются ядром системы на основании метаданных (для специальных случаев также предусмотрен ручной режим). Каждая проекция соответствует классу и содержит все его поля, включая поля суперклассов. Формат именований будет определен позже. У класса может быть несколько проекций, например проекция для работы только с актуальными версиями объектов (при включенной версионности), для логически удаленных объектов или для объектов в контексте языка локализации данных.
Приложения, работающие с БД, не имеют прямого доступа к таблицам: они взаимодействуют только с проекциями или вызывают хранимые процедуры.
Объекты имеют унифицированную и сквозную систему идентификации. Атрибут ObjectID класса Object является уникальным не только в пределах базы данных (узла), но и всей системы. Таким образом решается проблема физической репликации данных между узлами распределенной системы при отсутствии дубликатов на уровне ключей. О логических дубликатах мы поговорим позднее в рамках другой статьи.
Взаимодействие с объектом осуществляется посылкой ему сообщения. Ядром системы для каждого класса поддерживается набор сообщений (событий), обработку которых может дополнить или изменить прикладной программист. Обработчик реализуется хранимой процедурой с заданной сигнатурой, например <Имя класса>_<событие>_<обработчик>. Вызов обработчиков производится ядром в соответствии с иерархией дерева классов: по сути все обработчики являются виртуальными методами. Прикладной программист может добавлять свои типы событий.
Все манипуляции с объектами осуществляются посредством операций с проекциями или прямой посылкой сообщений. Проекции допускают весь стандартный набор операций для обычных таблиц: выборку, вставку, модификацию и удаление. Подобные операции рассматриваются как посылка сообщений (создать, изменить, удалить) всем объектам, попавшим во множество, определяемое SQL-запросом. Таким образом, обработка объектов через проекции будет ориентирована на множества, а не на последовательность операций, присущих популярным императивным объектно-ориентированным языкам типа Java, Delphi, C# и др. Ведь SQL — декларативный язык: вы только задаете «что сделать», а «как сделать» — решает интерпретатор на уровне СУБД. Впрочем, работа через посылку сообщений отдельным объектам позволяет использовать и традиционный императивный стиль программирования.
Метаданные. Поддерживается структурное описание классов объектов и связей между ними. Метаданные служат для автоматической генерации таблиц, проекций и триггеров/хранимых процедур, реализующих механизмы описанной выше объектной модели.
Версионность. Ядро предоставляет базовые возможности для поддержки версионности. Версионность декларируется на уровне метаданных класса; это означает, что для всех атрибутов включается история. Идентификатор является исключением: он уникален и неизменен на всем протяжении жизненного цикла объекта. Более того, уникальность гарантируется и после «смерти» — логического и последующего за ним физического удаления.
В обычном режиме объекты удаляются из БД только логически, т.е. перестают быть видимыми в своей проекции. Физическое удаление является внештатным режимом, поддерживаемым для специальных случаев, — например, в БД с высокой динамикой поступления и удаления информации.
Безопасность. Кроме системы безопасности самой СУБД ядро имеет собственную подсистему расширения. Используются механизмы идентификации и проверки подлинности (аутентификации) уровня СУБД, но пользователь СУБД при этом ассоциируется с профилем пользователя АИС.
Мы будем использовать систему безопасности на основе матриц доступа или, по терминологии Windows, списков доступа (ACL — Access Control List). В простом варианте это значит, что в системе хранятся соответствия между субъектом (пользователем, группой), имеющим доступ, объектами, к которым осуществляется доступ, и методом доступа к объектам.
В минимальном варианте предоставляются возможности по управлению доступом как на уровне класса (ко всем объектам данного класса), так и на уровне экземпляров (объектов).
Следующий уровень — ограничения на посылку событий, т.е. выполнение операций с объектами.
Далее, возможно реализовать ограничение на уровне доступа к отдельным полям класса.
Определяемые права можно группировать в роли и назначать их не только конкретным пользователям, но и рабочим группам (ролям).
Расширив описания на уровне метаданных, в принципе будет несложно реализовать и другие системы безопасности, например на основе мандатного доступа. Для этого придется модифицировать механизмы автоматической генерации проекций и, возможно, хранения информации.
Предварительные итоги
Несмотря на то что некоторые решения остались за рамками статьи, мы подведем промежуточный итог проектирования в виде концептуальной схемы базы данных ядра нашей будущей системы. Схема будет разделена на две части:
- базовые структуры самого ядра и метаданных,
- базовые объекты и сервисы ядра.
Физическую схему для СУБД PostgreSQL 8 и особенности реализации мы рассмотрим в рамках второй части публикации.
Продолжение следует.

Рис.2. Концептуальная модель БД. Структуры ядра и метаданные
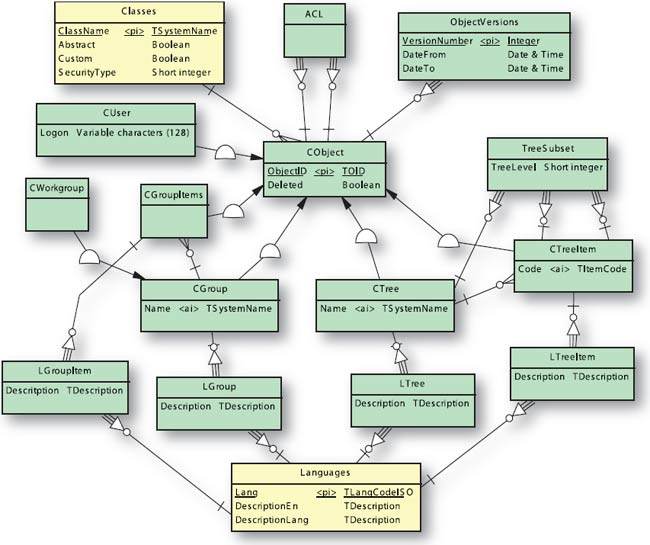
Рис.3. Концептуальная модель БД. Базовые объекты и сервисы
Приложение. Методы отображения: основные понятия и термины
Можно выделить три основных метода отображения классов объектов на реляционную схему БД.
- Хранение всех атрибутов (полей) в одной таблице.
- Группировка общих атрибутов в одной таблице и разнесение уникальных атрибутов подклассов по связанным таблицам.
- Представление каждого класса в виде отдельной таблицы.
Первый метод не относится собственно к реляционной модели и может рассматриваться только как средство оптимизации. Остальные методы используются CASE-средствами проектирования базы данных, например ErWin или PowerDesigner, и обозначаются как «полный/неполный подтип» (complete/incomplete subtyping) со схемой «атрибуты подкласса в новой таблице» (inherit only primary attributes, метод 2) и «наследуемые атрибуты добавляются к таблице подкласса» (inherit all attributes, метод 3).
В ОРП, поддерживающих выбор метода генерации схемы БД, например JDO, обозначения несколько иные. Первый метод называется «плоским отображением» (flat mapping), остальные методы реализуются с помощью либо «вертикального отображения» (метод 2, vertical mapping), либо «смешанного отображения» (методы 2 и 3, mixed mapping).
Сергей Тарасов, май 2007.
Статья также опубликована в журнале "Мир ПК" №7-2007.