Управление качеством данных на основе алгоритмов нечеткого поиска
Управление качеством данных на основе алгоритмов нечеткого поиска или как избавиться от дубликатов в базе данных
Вторая, переработанная версия статьи для научной публикации в свободном доступе: Контекстно зависимый способ поиска нечетких дубликатов в реляционных базах данных
Проблемы
Разработчик автоматизированных информационных систем (АИС) сталкивается с проблемой управления качеством данных. Строгого определения этому понятию нет, поэтому я воспользуюсь некоей «усредненной» трактовкой: это обеспечение такого состояния информации в хранилище, которое удовлетворяет требованиям пользователя по критериям достоверности, актуальности, логической полноты и непротиворечивости, отсутствия дублирующей информации.
Для выполнения всех перечисленных требований понадобится целый комплекс мер, одной из составляющих которого будет обеспечение отсутствия дубликатов.
В любой АИС можно выделить два основных типа дублирования информации:
- дублирование атрибутов, имеющих жестко заданную структуру (формат) содержания;
- дублирование атрибутов, не имеющих жестко заданной структуры (формата) содержания, т. е. слабоструктурированных.
В первом случае речь идет о различных кодах по отраслевым, муниципальным, федеральным и международным справочникам и классификаторам, идентификаторах сущностей, используемых в качестве ключевых атрибутов поиска (номера документов, счетов, телефонов, ПИН-коды и т. д.). Во втором случае мы имеем дело с разнообразными именами собственными, используемыми людьми для идентификации: фамилии, названия книг, фильмов, песен, фирм и т. д. Сюда же относятся адреса, содержащие названия улиц, номера строений и т.п., хранимые в одном атрибуте типа строкового поля «Адрес».
Проблема дублирования жестко структурированных атрибутов решается ограничением на ввод данных в соответствующие поля. Например, можно позволить ввод только разрешенных символов в заданном формате либо выбирать все допустимые значения атрибута из справочника. Поиск дубликатов в этом случае ведется по точному совпадению и не вызывает сложностей.
Ситуация со слабоструктурированными полями несколько сложнее, так как невозможно использовать ограничения формата (иначе это будет первый случай) и зачастую нельзя применять словари-справочники, поскольку их требуемый объем может выйти за разумные пределы и многократно превысить размер основной информации АИС. Представьте себе размер географического справочника адресов для небольшого отдела, занимающегося международной рассылкой писем. Еще труднее оценить затраты на поддержание такого справочника в актуальном состоянии, они могут превысить расходы на содержание всего отдела.
Решения
Для проверки дублирования слабоструктурированной информации нам помогут алгоритмы нечеткого поиска, позволяющие находить данные на основании неполного совпадения и оценки их релевантности - количественного критерия схожести. Следует учитывать, что данные алгоритмы не дают 100% гарантии от ошибок, то есть сохраняется вероятность того, что будут пропущены дублирующие данные или, наоборот, данные будут распознаны как дубликаты, не являясь таковыми. Поэтому для достижения наилучшего результата может быть необходимым участие человека.
Общий принцип применения алгоритмов для поиска дубликатов следующий:
- Производится вычисление некоторого показателя соответствия ("похожести") двух символьных строк, например, дистанции (расстояние) или релевантности.
- Данный показатель приводится к относительной шкале соответствия в интервале от 0 до 1 (0 - полное несовпадение, 1 - полное совпадение). В дальнейшем эта шкала легко может быть приведена к процентному виду, удобному для восприятия человеком.
- Экспериментальным путем для тестового массива данных определяется нижний порог автоматической обработки (Пa), за которым количество ошибок распознавания дубликатов становится неприемлемым. Определяется также нижний порог ручной обработки (Пp), за которым поиск выдает практически одни ошибки.
- Пa может быть использован для дальнейшей уточняющей обработки дубликатов в автоматическом режим, оставляя найденные элементы со значениями соответствия ниже Пa, но выше Пp для обработки человеком.
Основными путями внесения и изменения информации в АИС являются:
- непосредственный ввод пользователями
- импорт данных из внешних источников
При пользовательском вводе требуется обеспечить минимальное время отклика системы, поэтому используемый на этом этапе алгоритм должен работать не столько точно, сколько предельно быстро. При этом Пa для данной операции может быть изменен в соответствии с требованиями по скорости поиска. Так как система распознавания не может предоставить 100% точность, пользователь должен также иметь возможность игнорировать подсказку системы и ввести данные. При таких условиях в базу данных неизбежно будет попадать часть некачественной информации, которая должна быть обнаружена в дальнейшем.
Таким образом, задачу выявления и устранения дубликатов можно разбить на три этапа:
- Выявление дубликатов на уровне ввода информации пользователями и их отклонение.
- Выявление дубликатов путем сравнения и анализа уже введенных данных в соответствии с заданным Пa и автоматическое удаление дублирующей информации.
- Анализ и обработка человеком результатов п.2., которые не могут быть обработаны автоматически (показатель соответствия ниже Пa но выше Пp).
Возможные реализации
В качеств основы для реализации системы распознавания был выбран метод N-gram [1], который обеспечивает быстрый поиск на основе словаря грамов (подстрок) и может быть использован на всех этапах. На этапе 1 все атрибуты поиска склеиваются в одну строку. Например, фамилия, имя и отчество будут обрабатываться как одна строка "ФИО". Данный способ формирования строк для сравнения дает недостаточно точный, но быстрый результат при поиске.
На этапе 2 результаты поиска этапа 1 уточняются, проходя дополнительную проверку путем вычисления релевантности и расстояний уже для отдельных атрибутов поиска с учетом различных весовых коэффициентов, подбираемых экспериментально. Например, если две строки с ФИО совпали с релевантностью 90%, но при сравнении фамилий получена релевантность 60%, то несмотря на 100% совпадения имен и отчеств можно отвергнуть результат первого этапа, как ошибочный.
Следует упомянуть о недостатке метода N-gram, который в некоторых случаях может оказаться существенным: большой размер производного множества подстрок (N-grams) относительно количества исходных строк. Так, если N=3, то для каждой строки будет сформировано M = L - N + 1 словарных элементов, где L - длина строки >= N (при L < N, M = 0 и поиск невозможен).
Например, если у вас имеется база данных на 50 000 абонентов, средняя длина ФИО равна 50 символов, то мощность множества подстрок будет составлять примерно 50 000 * (50 - 3) = 2 350 000 элементов. При этом количество уникальных элементов, т.е. словаря, которое напрямую зависит от длины подстроки N, будет существенно ниже (экспериментально была получена разница примерно в 2 порядка), и, следовательно, вам будет затруднительно организовать быстрый поиск по такому множеству используя стандартные средства реляционной СУБД в виде индексов. Избирательность (selectivity) такого индекса будет мала, что может привести к отказу от его использования оптимизатором запросов. Решением данной проблемы при большом количестве данных для словаря является увеличение длины N.
В качестве нестрогого доказательства применимости данного решения можно рассмотреть функцию максимального количества элементов словаря (уникальных элементов множества) в зависимости от размеров подстрок и алфавита. Эта функция будет давать верхнее значение в предположении, что размещения символов алфавита по N равномерно распределены в строках. Чем меньше равномерность, тем меньше будет количество уникальных элементов. На практике равномерность при небольших N далека от идеальной, но она увеличивается с ростом N, и в предельном случае, когда N равно длине строки, при отсутствии точных дублей строк, мы получаем полностью равномерное распределение. Пусть N - длина подстроки, m - количество символов в алфавите, включая пробел и знаки препинания. Тогда количество возможных размещений с повторениями из m символов алфавита по N вычисляется в соответствии с известной формулой комбинаторики и равно mN. Это значение и будет являться самой верхней и грубой оценкой (пренебрегаем ещё и тем, что далеко не все размещения встречаются и допустимы в языке словаря) количества уникальных элементов словаря. Таким образом, при увеличении N количество уникальных элементов растет, как степенная функция.
Рассмотрим более подробно пример реализации системы распознавания дубликатов для списка фирм с использованием СУБД MS SQL 2000. Пусть фирма характеризуется следующим набором атрибутов.
| Атрибут | Тип | Примечание |
|---|---|---|
| Название фирмы | строка до 60 символов | |
| Почтовый индекс | строка до 20 символов | |
| Страна | строка до 40 символов | ссылка на значение из справочника |
| Административный округ (штат, край, область) | строка до 20 символов | |
| Населенный пункт (город) | строка до 40 символов | |
| Адрес | строка до 80 символов |
Для распознавания дубликатов на первом этапе мы будем использовать строку, составленную из всех перечисленных атрибутов, общая длина которой может достигать 260 символов.
Предположим, что в базе данных имеется 20 000 записей со средней длиной строки 150 символов. При таких параметрах выбираем длину подстроки N = 4. Таблицы для хранения списка фирм и словаря будут выглядеть так:
CREATE TABLE Company (
OID int not null identity(1, 1),
Name varchar(60) not null,
Country varchar(40) not null,
ZIPCode varchar(20) not null,
State varchar(20) not null,
City varchar(40) not null,
Address varchar(80) not null,
CONSTRAINT PK_Company PRIMARY KEY (OID)
)
GO
CREATE TABLE CompanyNGrams (
OID int not null,
NGram char(4) not null,
NGramCount smallint not null,
CONSTRAINT PK_CompanyNGrams PRIMARY KEY (CompanyID, NGram),
CONSTRAINT FK_CompanyNGrams_Company
FOREIGN KEY (CompanyID) <span lang="en-us">REFERENCES</span> Company(OID)
)
GO
Для первоначального заполнения множества подстрок (таблицы CompanyNGrams) и последующего её поддержания в согласованном со списком фирм состоянии (например, используя триггер), нам потребуется функция разбиения строки на подстроки (грамы). Вот пример функции, возвращающий множество подстрок (грамов) исходной строки в виде таблицы.
CREATE FUNCTION dbo.StrToGrams(@Str varchar(300))
RETURNS @RetSubstrs TABLE (NGram char(4), NGramCount smallint)
AS
BEGIN
DECLARE @GramLen integer,
@i integer,
@StrLimit integer,
@CurGram char(4)
SELECT @i = 1,
@GramLen = 4
SELECT @StrLimit = len(@Str) - @GramLen + 1
WHILE @i <= @StrLimit BEGIN
SELECT @CurGram = substring(@Str, @i, @GramLen)
UPDATE @RetSubstrs SET NGramCount = NGramCount + 1 WHERE NGram = @CurGram
IF @@rowcount = 0
INSERT INTO @RetSubstrs (NGram, NGramCount)
VALUES (@CurGram, 1)
SELECT @i = @i + 1
END
RETURN
END
Для первоначального заполнения таблицы множества подстрок CompanyNGrams можно воспользоваться приведенной выше функцией разбиения на грамы следующим образом:
DECLARE @CurOID int, @Str varchar(300)
SET @CurOID = 0
WHILE 1 = 1 BEGIN
SELECT @CurOID = min(OID) FROM Company WHERE OID > @CurOID
IF @CurOID IS NULL break
SELECT @Str = Name + Country + ZIPCode + State + City + Address FROM Company
INSERT INTO CompanyNGrams (CompanyID, NGram, NGramCount)
SELECT @CurOID, NGram, NGramCount FROM dbo.StrToGrams(@Str)
END
Для поиска дубликата следует сформировать строку для поиска, разбить её на грамы (подстроки) и вычислить релевантность по отношению к другим строкам, хранящимся в БД и которые мы предварительно разделили на подстроки.
Релевантность двух строк S1и S2 при длине грама (подстроки) N вычисляется по следущей формуле:
R = (NGramMatch(S1, S2) + NGramMatch(S2, S1)) / (NGramCount(S1) + NGramCount(S2))
NGramCount(S) = (len(S) - N + 1), где len(S) - длина строки S
NGramMatch(S1, S2) = сумма совпадений всех подстрок из S1 в строке S2
Тогда для поиска похожих строк можно использовать следующую функцию, состоящую всего из одного оператора SELECT
CREATE FUNCTION Company_SimilarList(@Name varchar(300), @MinRelevance float)
RETURNS TABLE AS
RETURN (
SELECT
Relevance = (convert(float, count(*)) /
(SELECT sum(NGramCount) FROM CompanyNGrams WHERE OID = S1.OID) +
convert(float, count(*)) /
(SELECT sum(NGramCount) FROM dbo.StrToGrams(@Name))) / 2,
DuplicateID = S1.OID
FROM CompanyNGrams S1 JOIN dbo.StrToGrams(@Name) S2 ON S1.NGram like S2.NGram
GROUP BY S1.OID
HAVING
(convert(float, count(*)) /
(SELECT sum(NGramCount) FROM CompanyNGrams WHERE OID = S1.OID) +
convert(float, count(*)) /
(SELECT sum(NGramCount) FROM dbo.StrToGrams(@Name))) / 2 >= @MinRelevance)
Примеры
Для реализации подсистемы поиска дубликатов в одной из CRM-систем (Customer Relationship Management — управление отношениями с клиентами) была использована следующая схема.
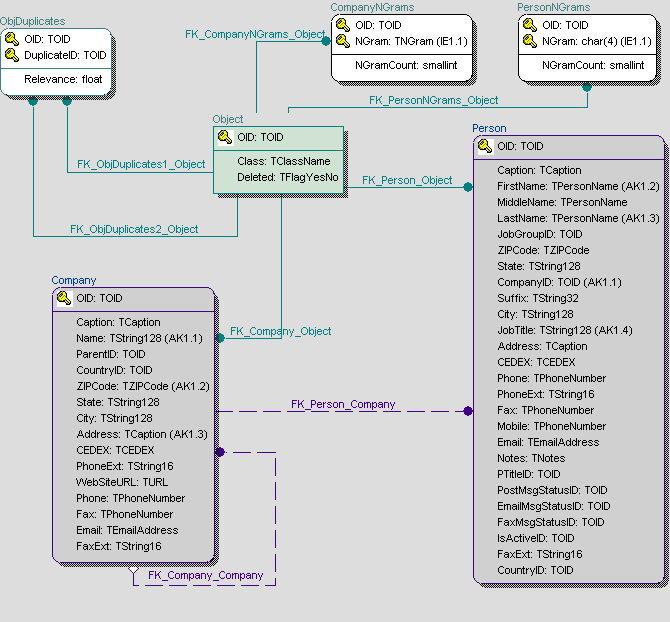
Схема базы данных в системе была выполнена в соответствии с принципом объектно-реляционного подхода, описанного нами ранее в серии статей «Проектирование ядра информационной системы».
Общий для всех классов предок Object отражается на одноименную таблицу. Связь с потомками (обобщение) и другие типы ассоциаций между классами унифицированы по ключу OID. Служебные таблицы CompanyNGrams и PersonNGrams хранят соответственно подстроки-грамы объектов классов «Компания» и «Контактное лицо». Таблица ObjDuplicates благодаря унифицированной связи по OID хранит связи между потенциальными дубликатами обоих классов.
Система расширяема. Для добавления нового типа поиска дубликатов, например, в географический справочник или каталог товаров вам потребуется только внести в систему таблицу хранения грамов и методы вычисления релевантности данного класса. Реализация с помощью хранимых процедур и функций заданной сигнатуры позволяет «включить» класс в подсистему нечеткого поиска без дополнительных издержек.
Разумеется, за универсальность нужно платить. Например, необходимо писать код проверки семантики классов объектов, добавляемых в таблицу дубликатов.
На первом этапе, при грубом сравнении без учета семантики следующие записи будут распознаны как дубликаты:
| "Гиперболоид Лтд", Пётр Петрович Гарин, Россия, Петербург, Крестовский остров д.1 |
| "Гиперболоид", Гарин Пётр Петрович, Россия, Санкт-Петербург, дача на Крестовском острове |
Однако, и такие вот записи тоже попадут в число "подозрительных":
| "Holmes and Co", Mr. Watson, UK, London, Baker street 226 |
| "Watson and Co", Mr. Holmes, UK, London, Baker street 226 |
Но на втором этапе при анализе с учётом семантики среди "подозрительных" записи из второго примера будут отбракованы вследствие низкой релевантности названий компаний и фамилий.
Литература
- Сайт, посвященный алгоритмам нечеткого поиска
Новая многоязычная версия сайта: https://ru.searchipedia.org/catalog/ - FAQ по "мягким" вычислениям
Сергей Тарасов, 2003-2007
Статья также опубликована в журнале "Мир ПК" №11-2007