The brilliance and poverty of microservices
This is the revised translation of my article published in "ITWeek" magazine January 24, 2019, text on the site
An expert tries to know more and more about less and less until he knows absolutely everything about nothing. And a philosopher tries to know less and less about more and more until he knows nothing about everything.
Daniil Granin, "Going Inside a Storm"

The subject of microservices is dangerous in itself: it is difficult to stay in the topic balancing on the edge of objectivity between the extremities of the fashion trend apologetic and the glorious technical past when clouds on the sky was whiter than actually.
I would start from far: the Agile development. Bertrand Meyer has succeeded to identify those little but useful things in the methodology which have a practical sense (Making sense of Agile methods, PDF) [1]. He had wrote the paper despite multiples negative feedback including ones published by authors of the "Manifesto" themselves (have a look on the articles of Andy Hunt, Ron Jeffries и Erik Meijer) [2,3,4]. Usually, any Agile method failure is "explained" by the incorrect management of the process.
The first thing that makes Agile related to microservices should alert a human having critical thinking skills: the argumentation of the technology choice is marginal enough. When Agile is opposed to the cascade method (waterfall) of development only, all microservices adepts crush only monolithic constructions using propaganda hammers. "What the monolith is? All but microservices!"
A beginner programmer may have an impression that the software world is consisted of systems made in granite using waterfall methods. No wonder that on such a black-and-white background the simple "bottom-up" and "function by function" development method well-known since the depths of the 1960s repacked in some slightly religious rituals is sold now as a "progressive and agile method".
On the other hand, the team size in Agile is a few people, up to a dozen at the limit. For such a team scale the construction of a bundle of microservices using an autonomous database, the coordination of their protocols in an "evolutionary way" without project documentation, and further maintenance seem to be realizable tasks. Technology is correlated with organization here.
Finally, according to UNIX philosophy [7], the use of many small specialized programs is preferable to large integrated packages and systems. This approach also fits well with the microservices development. It's hard to imagine a transactional DBMS or a publishing system made in the architecture of a swarm of mono-functional command line utilities. However, a pipeline processing of graphic files by user scripts looks naturally in such a scheme.
Many articles subjecting microservices have been published last years; this illustrates well how a so-called "hype cycle" works (Gartner) [5]: Agile is descending into the "Trough of Disillusionment" whereas microservices are still around the "Peak of Inflated Expectations".
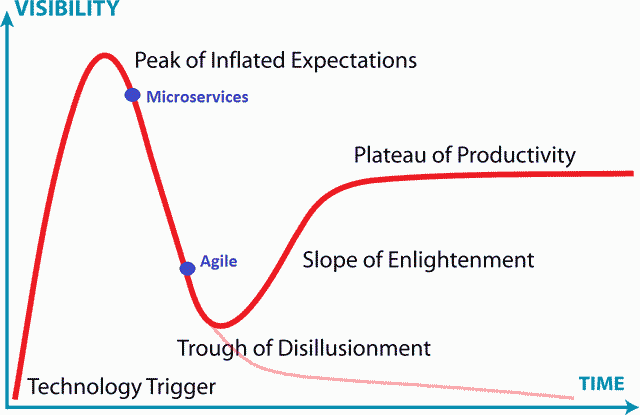
Getting rid of illusions does not mean yet getting rid of drawbacks and limits: many technologies had been abandoned never reaching the plateau of productivity. Some technologies was waiting for decades, for example, the first industrial implementations of .NET are dated from the mid to late 1960s [6].
Let's remember why previous attempts to introduce microservices did not gain much success so a beginner programmer may not even suspect their existence.
N microservices is the SOA concept reduced to absurd when N approaches infinity.
Me
Microservices-1: the patchwork quilt of automation
In the early 1980s IBM was starting to sell personal computers (PC) to enterprises; PC had been connected soon in local area networks (LAN). Whereas old applications was running on a single mainframe then now each department or even a user had got its own computer. Using these computers had reduced the dependence on the mainframe which was having a hard workload constantly with critical tasks of enterprise management. In addition of local tasks, the decentralization had been took away the mainframe functions having the implementation that was making users unhappy. The golden age had come for PC programmers, the work was continuing for years. However, mainframe programmers was considering these PC programs not really serious.
A typical application of that time had a dozen data files, two or three dozen screen forms, and several thousand lines of program code. Fully autonomous, "copy deployment" application allowed to scale horizontally and improve reliability. Is the computer broken? No matter, we move to another one in just a quarter of an hour: programs are copied, yesterday data is restored from a floppy disk, a user continues to work. Exchange of information is implemented as file protocols including the famous "floppy net" as a carrier. Whatever the application of the early PC era was a real "microservice" combined with front-end.
Sometimes this approach was producing solutions that may seem absurd today. For example, there were book-keeping programs created to maintain only one specific account. The data periodically imported from a bunch of such programs were integrated into other program calculating the balance.
Despite meeting the needs of multiple users and departments this automation approach reached soon the point of disillusionment. Programs was solving well their small problems but getting integrated information became a big problem. Any scenarios of the common work of two programs written for different departments looked like a fantastics at all. The data were duplicated many times, and it was not easy to find the most reliable source because the relevance was maintained only within the corresponding functionality scope. The modification of a client address in the delivery service did not affect the marketing mailings in any way. The changes of a product specification did not affect its prime cost. New department were created for collect and analyze the management information having different formats and relevance. Today such a department would be called "business intelligence".
Microservices-1 period has called the "patchwork automation" or "island-like automation". Sure, small standalone programs are suitable for particular functions but a subsequent integration and maintenance turn into a real hell even having coordinated information exchange interfaces. The architecture of enterprise information systems moved quickly to integrated solutions. Initially these solution were developing on the data file sharing (file-server), then on the basis of client-server technology which soon evolved to a multi-tiers one. Some standalone programs survived as functional add-ons working with data of an integrated system and its infrastructure.
Microservices-2: CORBA strikes back
The 1990s was the evolution of two-tier client-server systems to multi-tier. Indeed, a business logic should be stored in the place where applications can reuse it at a minimal cost. The architecture that transform a DBMS into an application server based on stored procedures is still alive but has a number of limitations. Therefore, a more general approach is to use layers of services.
There are many articles and books about the rise and decline of CORBA technology [8,9,10]. CORBA proposed the standardized approach to building multi-tier distributed systems starting from the definition of interfaces up to the using of ready-made standard services such as naming, alerting, transaction or security ones. Like the web services technology, CORBA did not impose decomposition on micro-components but such an architecture was looking quite natural already at the interface design and deployment planning stages. The system as a bundle of small services interacting over a common bus. Integrator dream was close to be realized and looked nice at least.
However the nice system have the price you should to pay, first of all, in the "money" of performance. Permanent network interactions of services perform at least a marshaling, transferring and unmarshaling of data. Asynchronous interactions require also queues and notifications. Decoupling into small autonomous components without taking into account their place inside the perimeter of functional subsystems leads soon to overloads.
For example, the client list service provides data that should be filtered according to user access rights. The choice that does not violate the purity of the concept is not large: to transfer the full list of corresponding object identifiers to the authorization service or to call authorization service function checking each element. When the ordering procedure requires detailed information about a product then the catalog microservice should be called for each item. Being autonomous the catalog service may not contain some items, suddenly. And so on...
The system response time increases as the length of the data lists and numbers of services in the chain. The data synchronization (in transaction, I hope) between autonomous services becomes more and more complicated after any modification depending on reference count between entities.
The evolution of the enterprise farm of microservices-2 was very similar to microservices-1 way: the small components were consolidated to the big ones having a size of corresponding domain-level subsystems. In fact, when service scope is a functional subsystem, then main data processing is inside. Indeed, the system analysis methods like SADT distinguish subsystem scopes according to strong and weak links between the objects of subject areas. However, such a module is already too large to be considered as a microservice. Can a payroll service be taken seriously for a "micro" one?
Meanwhile CORBA has been replaced by simpler (but less functional) architectures based on web services that ping-pong XML and later JSON flows on the top of plain text protocols. The carrier technology had changed but the service-oriented architecture has adopted although there is not much left of the “micro” prefix.
Microservices-3: the road to clouds paved with good intentions
Resurrecting of microservices subject [11,12,13] is well correlated with a large campaign of migration of IT infrastructures to the "cloud". Indeed, a perfect component to use in the cloud should be completely autonomous and have no state. A flawless microservice can be unlimitedly scaled horizontally to ensure its high availability and load balancing. Why not try to sell to a client the redevelopment of its software in addition to the migration?
In the real world of enterprise applications it's difficult to find the place of such a microservice. A specific batch processing using other services as inputs and outputs of information may be a good example when the enterprise has already a so-called core system that supports all main critical business processes, and accessible for integration through its web services. However, a redevelopment of the core system using microservices will lead to the same problems that had caused microservices-1 and 2 to disappear in the depths of the consolidation. These problems depend on the more global choice between centralized and distributed architecture. Indeed, microservices are only one of many implementations of a distributed system.
Unfortunately, the claim of higher reliability of microservice development is not related to the technology: this is just another attempt of isolation of program code. Indeed, vertical (full-stack) teams and developers hurt to reuse lower level components without the assistance of a horizontal group of designers. This option may be even banned administratively. Many years ago Microsoft developers had told at a conference that the formatting component in an Excel cell and a corresponding one for Word table are completely independent. Although you have to write twice the code and tests but changing this function in Excel will not cause side effects in Word. In the enterprise applications world, only few customers are able to pay many times for reinventing bicycles, whereas regression risks due to changes in other parts of the system can be minimized by integration tests.
When microservices have to keep its state, a designer meets the opportunity of the first step of consolidation, placing the data of several services in one database. Such a step is not obvious for the service of collecting primary information from sensors, but required to manage the catalog of products: the separation of order items from of the catalog leads to loss of data integrity and to the need of synchronization of the distributed micro-database.
By the way, did you wonder how much easier and cheaper to administer one even a large transactional database, instead of dozens of smaller ones linked by synchronization procedures?
Note. The subject of distributed databases was developing actively since the early 1990s when slow communication channels did not allow working remotely with a centralized database. Therefore local offices had their own databases linked with the central one. Data replication technologies, merge conflict resolution, and two-phase transaction commit was well known at the time. As the channel throughput and reliability had been improved and increased such architectures were abandoned in favor of centralized ones, firstly because of maintenance cost.
Having decided to share the database to a bunch of microservices, a designer takes a second step towards the consolidation. Any local interaction of modules is much faster than the network one. Therefore, displaying a complex document on the user's screen that requires dozens of services in more than several seconds starts the redevelopment of the whole subsystem from micro-parts compiling them into a larger module with a shared memory.
A radical third step may be needed when virtualization performance is insufficient. You may need to say goodbye to all the advantages of packing services into containers. It's a good moment to remember how the automated system of ordering and selling train tickets for the whole USSR had been running successfully on several mainframes which performance is much times lower that one of a modern phone in your pocket.
Perhaps such steps will not be required, the stored state will be really microscopic, and the network interaction will be enough to ensure the required performance. Then be glad for the successful project and the distributed architecture meeting the requirements.
The king is dead, long live the king?
Returning to the Gartner's "hype cycle graph" I would make an optimistic forecast. The current re-branding of Microservices-3 will remain as a technology but its appliance scope will be revised according to well known limitations of a distributes systems. My optimism is based on the stack of already proven web services technologies and possibilities to deploy a large number of components on the cloud. In addition to architectural limitations, the integration of microservices inside enterprise systems will be prevented by the strong consistence and standardization of the environment whereas microservices development is targeting the autonomy of weakly tied parts and theirs developer teams.
Experience says: you can not fight with trends but you can deal with fluctuations. Hope your personal trend will be the choice of architecture based on the system requirements, not the position of a technology on the hype cycle graph.
References
1. Bertrand Meyer, "Making sense of agile methods", November 2017, http://se.ethz.ch/\meyer/publications/me...
2. Andy Hunt (co-author of "The Agile Manifesto"), "The Failure of Agile", June 2015, https://toolshed.com/2015/05/the-failure...
3. Ron Jeffries (co-author of "The Agile Manifesto"), "Developers Should Abandon Agile", May 2018, https://ronjeffries.com/articles/018-01f...
4. Erik Meijer, "Agile must be destroyed, once and for all", January 2015, https://www.theregister.co.uk/2015/01/08...
5. Hype cycle, Wiki, https://en.wikipedia.org/wiki/Hype_cycle
6. ALMO is .NET in the year of 1967, https://www.arbinada.com/ru/node/1333
7. Eric Raymond, "The Art of Unix Programming", Addison-Wesley, 2003, https://en.wikipedia.org/wiki/The_Art_of...
8. Serguei Tarassov, "Brain defragmentation. Inside of programming", Piter publishing house, 2013, https://www.ozon.ru/context/detail/id/34...
9. Michi Henning, "The Rise and Fall of CORBA", ACM Queue, Volume 4, Number 5, June 2006, перевод С. Кузнецова, https://queue.acm.org/detail.cfm?id=1142044
10. Dirk Slama, Perry Russell, Jason Garbis, "Enterprise CORBA", Prentice Hall Ptr; 1st edition (March 3, 1999), https://www.amazon.com/dp/0130839639
11. Sam Newman, Building Microservices, O′Reilly, February 2015
12. Martin Fowler, James Lewis, "Microservices. A definition of this new architectural term", March 2014, https://martinfowler.com/articles/micros...
13. Andrei Furda, Colin Fidge, Olaf Zimmermann, Wayne Kelly, Alistair Barros. Migrating Enterprise Legacy Source Code to Microservices. On Multitenancy, Statefulness, and Data Consistency, IEEE Software, May/June 2018, IEEE Computer Society
14. Sean Kelly, "Microservices – Please, don’t", September 14, 2016, https://riak.com/posts/technical/microse...
15. Dave Kerr, "The Death of Microservice Madness in 2018", https://www.dwmkerr.com/the-death-of-mic...
16. Alexandra Noonan, "Goodbye Microservices: From 100s of problem children to 1 superstar", July 10, 2018, https://segment.com/blog/goodbye-microse...