"Если б я имел слона..."
О PostgreSQL я достаточно подробно упомянул в книжке "СУБД для программиста". Несмотря на явное лидерство SQL Server в приводимых примерах программирования работы с СУБД, PostgreSQL занимал почетное второе место. Однако на практике, поддерживая работу приложений с несколькими СУБД, я бы поставил PostgreSQL на "первое" место с конца. Почему?

Фото А.Сасин, газета "Орловская правда"
Есть поговорка, в оригинале про коня, звучащая примерно так: "Если б я имел слона, это был бы номер. Если б слон..." Да, если б слон, в обратном направлении, то "я б, наверно, помер".
Обеспечивая совместимость работы с постгресом, меня не покидает ощущение, что "слон" втайне планирует совершить описанные в поговорке действия. Не со злым умыслом, конечно. Но в итоге-то, какая разница?
Почитывая русскую фейсбук-группу по постгресу "Слон в ушанке", я было вознамерился создать традицию пятничного вопроса об очередной "особенности", которую даже как-то неприлично называть ошибкой. Не комильфо. "Это не баг, это фича!" (с)
Предположим, запускаете вы такой запросец на четырех СУБД
SELECT id, ' ' AS col1 FROM mytable
Какой будет тип возвращаемой колонки col1? Не спешите с ответом.
SQL Server, Firebird и Oracle возвращают честный char(1). PostgreSQL возвращает неизвестный тип. Действительно, какой же тип может иметь строковый литерал? Только неизвестный. Проблема обходится явным приведением к нужному типу.
Теперь запускаем другой запрос на четырех СУБД (для SQL Server используется + вместо ||).
SELECT surname || name AS full_name FROM persons
Пусть колонки surname и name имеют тип varchar(30). Какой будет тип возвращаемой колонки full_name? И снова не спешите с ответом.
SQL Server, Firebird и Oracle возвращают ожидаемый varchar(60). PostgreSQL возвращает text, то есть строковый безразмерный тип. Действительно, если соединить две строки, имеющие максимум по 30 символов, то в военное время общая длина в символах может оказаться больше 60. Проблема снова обходится только явным приведением к нужному типу.
Есть ли в постгресе бинарный тип фиксированной длины? Нет, надо использовать безразмерный bytea. Неважно, что у тебя, скажем, ключи или хэш строго по 32 байта и что ты хочешь через метаданные СУБД как-то отличить их от безразмерных колонок, хранящих документы в двоичном формате. Эта проблема, к сожалению, уже не обходится никак.
Константу числового типа в запросах PostgreSQL нужно явно приводить к монетарному типу, иначе запрос выдает ошибку.
SELECT * FROM prices WHERE price > 10
Error: operator does not exist: money > integer
Прозрачное для приложений секционирование таблиц на уровне хотя бы SQL Server 2005? Нет, не слышали. Зато есть три других способа, возвращающих разработчика куда-то в бурные 1990-е.
Последние годы в постгрес вносится много изменений, связанных с поддержкой неполно структурированных данных (XML, JSON). Само по себе неплохо, конкуренция с MongoDB и компанией, но, как видно, такая эволюция идет в ущерб привычным реляционным подходам.
Резюмируя.
Если приложение разрабатывается с привязкой к СУБД, то выбор постгреса не будет ничем особенно хуже, чем других. Постепенно вы научитесь обходить щедро раскиданные грабли и освоитесь с местным колоритным "вуду". С поправкой на то, что под Windows придется попрощаться с производительностью, достижимой под Linux. Со слов самих разработчиков, поддержка Windows в постгресе реализована с помощью костылей и подпорок, так как уровень знаний внутренностей Windows у программистов был недостаточен.
Но если речь идет о поддержке нескольких СУБД, то я бы поставил постгрес в конец всей названной "четверки". Даже при всем моем сложном отношении к Ораклу из-за тридцатилетнего тяжелого наследства и, мягко говоря, недружественности Firebird к администраторам БД.
Да, чуть не забыл. Вчера, 12 апреля, спустя 11 лет закончилась поддержка SQL Server 2005. С днём космонавтики вас!
pgAdmin 4 и DROP FUNCTION
(дополнение от 2017-06-15)
"Ничего не сделал, только зашел" (с) кино
К своему великому счастью год не обращался к теме Постгреса, но в связи с переустановкой серверов разработки недавно пришлось "взять в руки шашки". Сразу обнаружилось, что pgAdmin 4 не только переписали на г... пардон, на новых технологиях, но и перестали поддерживать версию 3.
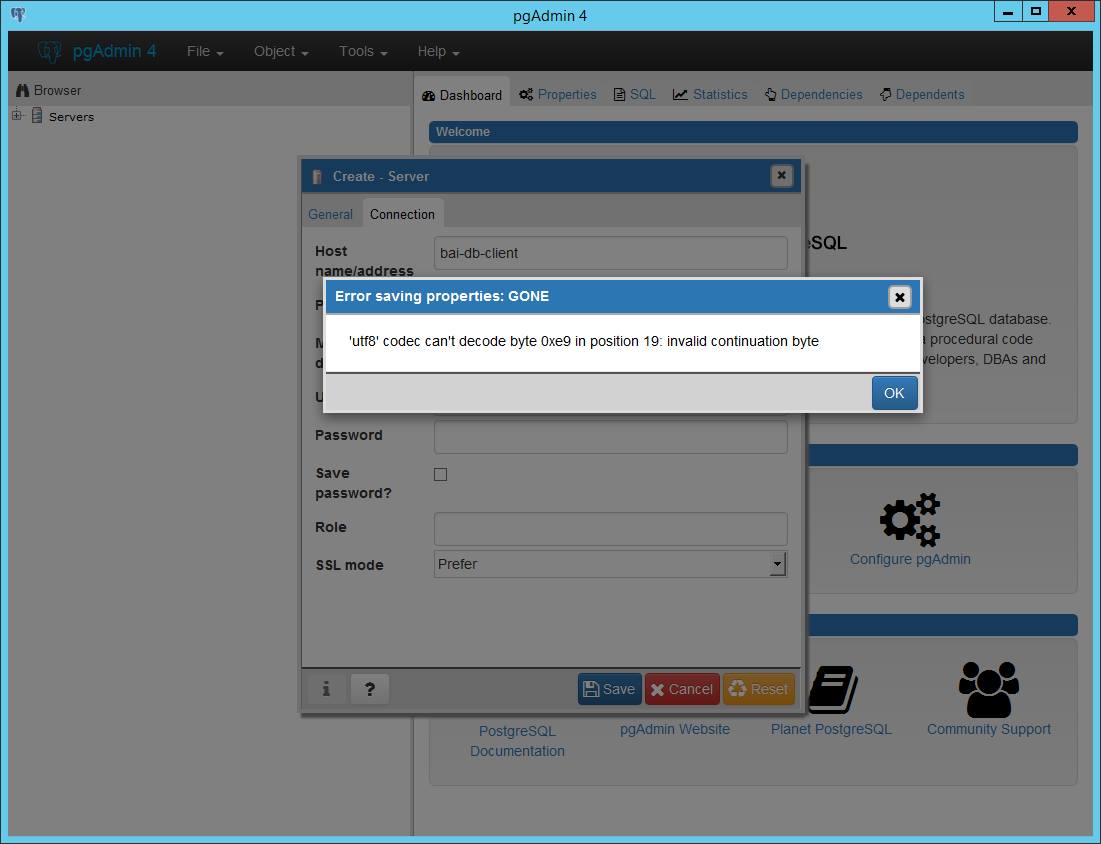
Версия 4-1.5 (четыре полтора) производит впечатление поделия, не работающего сразу после установки. Посему возник естественный вопрос: "Что нынче рекомендует ЦК ВЦСПС для администрирования нашей главной хипстерской импортозамещательной СУБД?" Однозначного ответа в фейсбучной группе не нашлось, некоторые лишь подтвердили мой вынужденный выбор последней доступной версии "тройки".
"Оставайтесь с нами, мы будем следить за развитием ситуации" (с)
Не далее как вчера в программе установки обновлений потребовалось превентивно удалять хранимые процедуры (в Постгресе - функции). К сожалению, оператор DROP не работает просто так, необходимо указать полную сигнатуру в виде
DROP FUNCTION my_func(int, int);
DROP FUNCTION my_func(int, int, int);
и т.д.
Концепт, весьма спорный, тем не менее ясен: функции в Постгресе можно перегружать, поэтому чтобы удалить нужную, надо специфицировать. А если надо удалить все функции заданного имени?
Stackoverflow предлагает много способов из разряда "стоя в гамаке". Пришлось использовать запрос со внутренними функциями, формирующий оператор DROP вместе с сигнатурой.
Всплыло даже такое дикое решение, как использование для функций отдельной схемы типа procs, которую можно удалять каскадом вместе со всеми хранимыми в ней функциями...
Вроде бы очередная мелочь, но дающая неплохое представление о том, как "проектируются" решения в базаре. "Прикрутить фичу", а там хоть трава не расти. Недоволен - код открыт, сам допиши.
Для сравнения, SQL Server не предлагает перегрузки хранимых процедур, но позволяет их нумеровать. Следующие вызовы выполняют разные код.
EXEC my_proc;1;
EXEC my_proc;2;
При этом DROP my_proc ожидаемо удалит всю группу my_proc. Ну, подумали люди не только про "фичу", но и про последствия её использования. Есть у проектировщиков глобальное видение системы.
P.S. 2017-12-04 по наводке от Дмитрия Белявского, коллега которогопознал ад сортировки Юникода в Постгресе.
При сортировке в юникодной локали PostgreSQL выдаёт записи в следующем порядке:
_aa_cd
Причина в алгоритме сравнения Unicode: при сортировке в локали базы в итоге символы подчёркивания игнорируются. Поведение хоть и документированное, но неочевидное.
Обходится проблема наложением на искомую колонку COLLATE "C", что даёт почти бинарное сравнение с учетом подчеркивания.