MongoDB как зеркало мировой СУБД-революции
Данная заметка послужила основой для одноименной главы книги "СУБД для программиста. Базы данных изнутри".
* * *
Несколько эпизодов из жизни NoSQL глазами YesSQL. Тема всплыла в результате исследования технических средств для проекта переработки существующей системы. Пуркуа бы и не па?
Для теста был выбран сценарий позволяющий:
- оценить пригодность СУБД к интенсивной вставке данных от множества устройств
- оценить простоту и производительность запросов к полученной таким образом базе данных
Тест вставки, или изгнание из рая
Тест интенсивной вставки данных от множества датчиков я ограничил 10 миллионами записей. Реальные объёмы на порядки выше, но зачем проводить долгое время за процессом, если вдруг и на таком количестве возникнут проблемы.
На сайте MongoDB была загружена последняя стабильная версия 2.0.2 для 64-разрядной Windows. В качестве альтернативы MongoDB выступал MS SQL Server 2008 R2 Developer Edition, тоже 64-разрядный (если у вас такого нет, тест пойдет и на бесплатном SQL Server Express 2005 и выше). Компьютер для обоих тестов использовался слабенький, уровня обычной рабочей станции под Windows 7, двухядерный Intel 2.6 GHz с одним медленным диском (5400 rpm, 300 Gb), но с 6 гигабайтами памяти.
Данные вставляются в коллекцию MongoDB и таблицу SQL Server, соответственно, имеющие одинаковую структуру. Соответствующие скрипты можно загрузить.
Для SQL-скрипта надо сделать пояснение. YesSQL - это мир транзакций. Если вы будете тупо построчно вставлять в таблицу данные, как будто перед вами плоский файл, то скорость будет в разы ниже, чем в случае файла. Поэтому запишите у себя в конспекте: для интенсивной построчной вставки в реляционную СУБД приложение должно сначала накопить массив строк, потом начать транзакцию, вставить эти несколько строк в таблицу и закрыть транзакцию.
В скрипте выбран пакет всего в 10 строк, который увеличивает скорость вставки в 5 раз по сравнению с построчным вбиванием данных.
MongoDB, цитирую does not use traditional locking or complex transactions with rollback, as it is designed to be lightweight and fast and predictable in its performance. В общем, согласен, если просто построчно вставлять записи в таблицу, то не-транзакционность окажется быстрее в любом случае.
Для продвинутых поясню, что пакетная вставка (BULK INSERT) не всегда приемлема по логике приложения. Стандартное использование - массовый импорт данных. Собственно, для BULK-копирования и тестировать особо нечего, оно или есть в СУБД, или нет. В MongoDB и SQL Server эта функциональность присутствует.
По итогам вставки получились два графика и цифры по объему получившейся базы данных.
Коллекция из 10 миллионов документов заняла 3,95 гигабайт, база данных SQL Server - 0,5 Гб (без компрессии), то есть в 8 раз меньше.
Скорость вставки
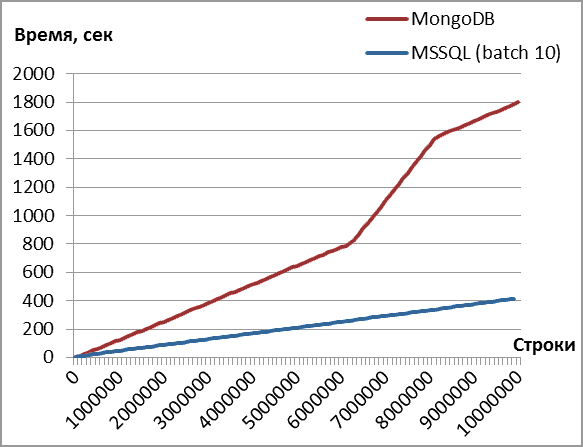
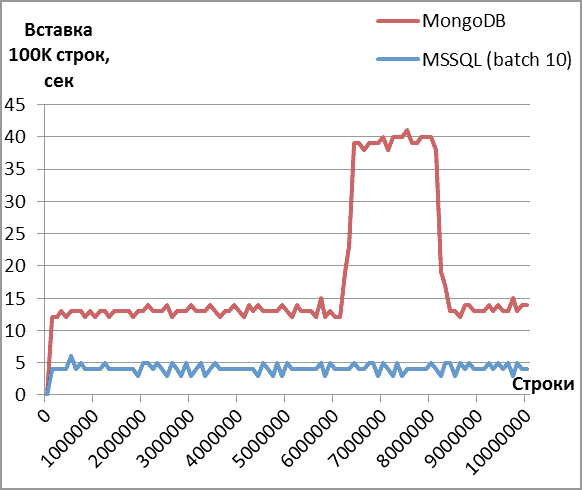
Хотя время вставки документа примерно в 3 раза выше, чем строки в таблицу (пачками по 10), оно может быть вполне приемлемым для логики приложения. Меня больше заинтересовал временный провал в производительности (горб на втором графике) и неуёмное желание MongoDB отожрать всю оперативную память: 4 Гб против 1 Гб SQL Server при выставленном лимите в 3 Гб.
Можно ли ограничить объем используемой оперативной памяти? Ответ MongoDB - нельзя. Запрос на изменения висит больше года на трекере и не встретил у разработчиков никакого понимания. В общем случае решение состоит в создании выделенного виртуального сервера под СУБД. Какие-то неофициальные советы можно найти поиском (например). Словом, остается надеяться на лучшее в будущем.
Поэтому для дальнейших тестов мне приходится делать перезапуск mongod для очистки памяти. В SQL Server для аналогичного эффекта просто очищаем буферы и кэш (DBCC).
О, этот кэш! Во второй части вы увидите, насколько он эффективен.
Запросы, или сошествие во адЪ
Пришло время применить полученную таблицу по назначению, нагрузив СУБД разными запросами.
Общее впечатление от MongoDB: я попал в эпоху даже не FoxPro 2, где встроенный SQL уже был, а куда-то в Clipper 87, увидевший свет летом 1987 года. "Клиппер" во всей красе, с его бесконечными обходами таблиц в циклах, явным выбором текущего индекса для поиска, наложениями фильтров, ручным суммированием и прочими давно забытыми «прелестями».
Клиппер, точнее, Harbour - проект 100%-совместимого с унаследованным клипперным кодом компилятора и его развитие, жив и здравствует. Польза открытых исходников и разработки сообществом очевидна, тогда как Микрософт ветку FoxPro после покупки и выпуска версии 3 долго изживал и таки "усыпил лиса" в прошлом году, оставив жить Access.
В MongoDb нет встроенных функций агрегации. Для нахождения сумм или средних величин нужно фактически написать свой аналог стандартных в SQL функций SUM() или AVG() на языке JavaScript или использовать более общий метод MapReduce.
Справедливости ради, надо сказать, что начиная с версии SQL Server 2005 особо одаренные программисты могут писать свои нестандартные функции агрегации на C#. Но я посоветовал бы вначале хорошо подумать о необходимости этого шага.
В случае, если запрос с агрегацией возвращает более 10 тысяч документов, использование MapReduce обязательно, иначе выдается ошибка. Таким образом, встроенным является только подсчет числа элементов в том числе уникальных. Но вот беда - использовать их можно только в применении к целым коллекциям, то есть вне контекста запросов с группировками. Так что, дорогие программисты, и для COUNT() с группировкой пишите рутинный типовой код на JavaScript.
Как отсортировать результаты запроса с группировкой? Ответ - никак, сделайте сортировку на клиенте. Диалог ниже оставляю без цензурных комментариев.
Q: How can I sort on the resultset of the group by operation?
A: Group currently just returns an object, so you should be able to sort easily client side
В результате код запросов с кратким и ясным синтаксисом декларативного языка SQL превращается в длинную кашу из императивных инструкций и параметров-деклараций. "Эволюцию" можно проследить ниже на примере использованных в тесте запросов. Добрые люди даже нарисовали вот такую картинку трансформации MySQL-запроса в MongoDB.
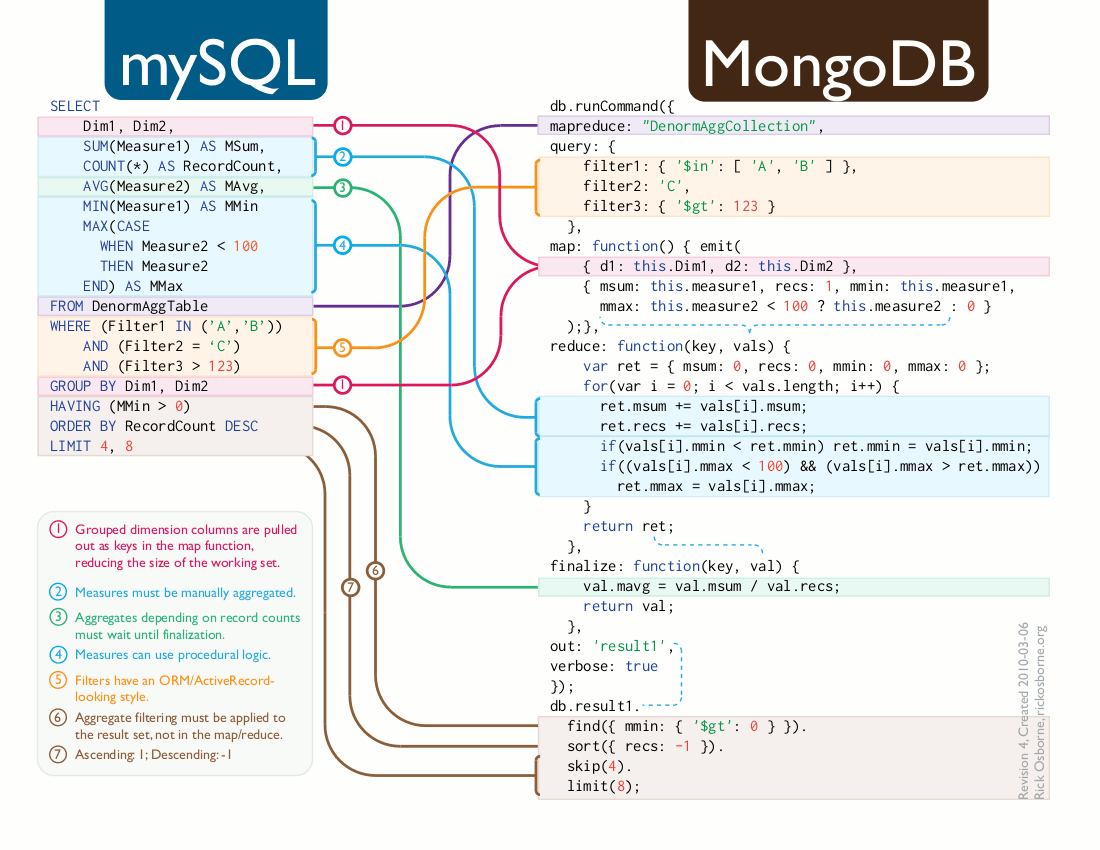
Запрос Q1
Поиск минимального и максимального значения дат в таблице/коллекции.
SQL Server
SELECT MIN(measureDate), MAX(measureDate)
FROM dbo.measuresData
MongoDB
var minDate = new Date(1900,1,1,0,0,0,0);
var maxDate = new Date(2100,1,1,0,0,0,0);
db.measuresData.group(
{
key: { },
reduce: function(obj, prev)
{
if (obj.measureDate.getTime() < prev.minMsec)
prev.minMsec = obj.measureDate.getTime();
else if (obj.measureDate.getTime() > prev.maxMsec)
prev.maxMsec = obj.measureDate.getTime();
},
initial: { minMsec: maxDate.getTime(), maxMsec: minDate.getTime() },
finalize: function(out)
{
out.minMeasureDate = new Date(out.minMsec);
out.maxMeasureDate = new Date(out.maxMsec);
}
})
.forEach(printjson);
Вариант MongoDB заставляет работать с представлением дат в виде числа миллисекунд от 01/01/1970, потому что прямое сравнение дат в функции вызывает ошибку TypeError: this["get" + UTC + "FullYear"] is not a function nofile_b:2
"Клипперный" опыт пригодился в MongoDB. Если построить индекс по элементу "measureDate", то можно найти крайние значения относительно простым способом: отсортировать по индексу в порядке возрастания и взять первый элемент, повторив процедуру в порядке убывания значений.
db.measuresData.ensureIndex({measureDate: 1});
db.measuresData.find({}, {measureDate: 1}).sort({measureDate: 1}).limit(1);
db.measuresData.find({}, {measureDate: 1}).sort({measureDate: -1}).limit(1);
Запрос Q2
Подсчет сумм целых и вещественных значений по состоянию и группе устройств. Запрос для MongoDB, напомню, не выполняет сортировку.
SQL Server
SELECT SUM(intVal), SUM(floatVal), stateId, groupId
FROM dbo.measuresData
GROUP BY stateId, groupId
ORDER BY stateId, groupId
MongoDB (не выполняет сортировку)
db.measuresData.group(
{
key: { stateId: true, groupId: true },
reduce: function(obj, prev)
{
prev.sumIntVal += obj.intVal;
prev.sumFloatVal += obj.floatVal;
},
initial: { sumIntVal: 0, sumFloatVal: 0.0 }
})
.forEach(printjson);
Запрос Q3
Подсчет общего числа устройств и количества уникальных устройств по состоянию и их группе.
SQL Server
SELECT
COUNT(deviceId),
COUNT(DISTINCT deviceId),
stateId, groupId
FROM dbo.measuresData
GROUP BY stateId, groupId
ORDER BY stateId, groupId
MongoDB (не выполняет сортировку)
db.measuresData.group(
{
key: { stateId: true, groupId: true },
reduce: function(obj, prev)
{
prev.count++;
},
initial: { count: 0 },
finalize: function(out)
{
out.distCount = db.measuresData
.distinct("deviceId", {stateId: out.stateId, groupId: out.groupId})
.length;
}
})
.forEach(printjson);
Журнал ядра БД показывает примерно 35 секунд для функции finalize на каждый цикл вычисления distinct из примерно 200 строк. Срочно обрываем запрос.
Для получения ответа в течение минут требуется построить индекс по элементам stateId и groupId, иначе запрос выполняется в течение почти 2 часов. Иными словами без оптимизации (вмешательства администратора БД) простой adhoc-запрос фактически не работает.
db.measuresData.ensureIndex({stateId: 1, groupId: 1})
Индекс строится 141 секунду (аналогичный в SQL Server – за 20 секунд). Размер БД вырастет до 4,2 Гб.
Перезапускаем запрос. Победа разума, с индексом цикл вычисления distinct снижается до 300 миллисекунд (в 100 раз). Третий перезапуск, время цикла выросло до 1,2 секунды, потом начинает снижаться до 300 мсек. Общее время: более 15 минут! Полное впечатление, что вместо осмысленного использования кеша, в память намеренно заносится мусор, только мешающий нормальной работе движка БД.
Запрос Q4
Подсчет сумм целых и вещественных значений по состоянию и группе устройств для заданного диапазона дат. В качестве диапазона выбрана 1 минута примерно в середине интервала между минимальным и максимальным значениями дат. Диапазон включает около 500К строк.
SQL Server
SELECT SUM(intVal), SUM(floatVal), stateId, groupId
FROM dbo.measuresData
WHERE measureDate BETWEEN '20120208 22:54' AND '20120208 22:55'
GROUP BY stateId, groupId
ORDER BY stateId, groupId
MongoDB (не выполняет сортировку)
var date1 = new Date(ISODate("2012-02-08T15:20:00.000Z"));
var date2 = new Date(ISODate("2012-02-08T15:21:00.000Z"));
db.measuresData.group(
{
key: { stateId: true, groupId: true },
cond: {measureDate: { $gte: date1, $lt: date2 } },
reduce: function(obj, prev)
{
prev.sumIntVal += obj.intVal;
prev.sumFloatVal += obj.floatVal;
},
initial: { sumIntVal: 0, sumFloatVal: 0.0 }
})
.forEach(printjson)
Запрос Q5
Подсчет общего числа устройств и количества уникальных устройств по состоянию и их группе для того же заданного диапазона дат.
SQL Server
SELECT COUNT(deviceId), COUNT(DISTINCT deviceId), stateId, groupId
FROM dbo.measuresData
WHERE measureDate BETWEEN '20120208 22:54' AND '20120208 22:55'
GROUP BY stateId, groupId
ORDER BY stateId, groupId
MongoDB (не выполняет сортировку)
var date1 = new Date(ISODate("2012-02-08T15:20:00.000Z"));
var date2 = new Date(ISODate("2012-02-08T15:21:00.000Z"));
db.measuresData.group(
{
key: { stateId: true, groupId: true },
cond: {measureDate: { $gte: date1, $lt: date2 } },
reduce: function(obj, prev)
{
prev.count++;
},
initial: { count: 0 },
finalize: function(out)
{
out.distCount = db.measuresData
.distinct("deviceId", {stateId: out.stateId, groupId: out.groupId})
.length;
}
})
.forEach(printjson);
Хронометраж запросов
Для MongoDB результаты без оптимизации ужасающие, а с оптимизацией, где она возможна, от "хуже" до "просто плохие". Со стороны SQL Server вся оптимизация свелась к построению кластерного индекса по полю measureDate (точнее, перестроению вместо имевшегося по первичного ключу measureId). В запросах Q2 и Q3 необходимо полное сканирование данных, поэтому оптимизация стандартными средствами (индексация) для SQL не производилась.
Вторые и третьи запуски хорошо иллюстрируют работу кеша СУБД.
| SQL Server | MongoDB | ||||||
|---|---|---|---|---|---|---|---|
| Запуски / время, сек | (1) | (2) | (3) | (1) | (2) | (3) | |
| Q1 | 7 | 1 | 1 | 190 | 185 | 189 | |
| Q2 | 8 | 3 | 3 | >7200 | |||
| Q3 | 26 | 20 | 20 | 345 | 341 | 349 | |
| Q4 | 8 | 1 | 1 | 22 | 22 | 22 | |
| Q5 | 15 | 10 | 12 | 141 | 141 | 141 | |
| После оптимизации | |||||||
| Q1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Q2 | 8 | 3 | 3 | 322 | 800 | 619 | |
| Q3 | нет | нет | |||||
| Q4 | 1 | 1 | 1 | 12 | 12 | 13 | |
| Q5 | 7 | 7 | 7 | 85 | 84 | 85 |
За кадром
За кадром остался интересный вопрос: "Кто исполняет ява-скрипты, ядро монго или же её клиент mongo shell?". Надеюсь на первое, потому что во втором случае речь вообще идет о не СУБД, а о менеджере записей (record manager), вроде приснопамятного BTrieve из локальных Novell-сетей 90-х годов.
Выводы, или вперед в прошлое
Помимо сложности написания простейших запросов, неприемлемого даже после оптимизации времени отклика, неэкономного физического хранения, неуправляемого использования оперативной памяти и многого другого, что я просто не смог охватить в небольшом тесте, MongoDB фактически не умеет использовать кеш запросов. Все перечисленное уже не дает возможности отнести СУБД к разряду "универсальных, просто с другой моделью данных".
Нет, ребята, модель здесь вторична, а об универсальности, как и о промышленном решении говорить пока преждевременно. Для использования NoSQL нужно иметь серьёзные основания.
Проще сказать, что не является причиной выбора NoSQL.
- Отсутствие компетенций в области баз данных и надежда обойтись без в дальнейшем;
- Протест квазимонополии "Big-3" (Oracle, IBM, Microsoft). Для этого есть PostgreSQL, Firebird и, с оговорками, MySQL;
- Использование вместо технических аргументов маркетинговые термины "мода", "современное течение", "прогрессивное направление" и т.д. На самом деле, модели данных NoSQL использовались еще в дореляционную эпоху.