Постраничная (пакетная, paging) выборка в SQL Server
От редактора. Данная версия статьи частично устарела, смотрите новый вариант с учетом изменений в SQL Server 2012
Материал этой статьи послужил основой для одной из глав книги "СУБД для программиста. Базы данных изнутри".
* * *
На дворе 2008 год, а разработчики MS SQL Server до сих пор не реализовали встроенную возможность ограничивать в запросах результирующую выборку номерами строк. Например, "выбрать заказы данного клиента, начиная с 10000-й строки и по 12000-ю". Нечто вроде простого и понятного:
SELECT O.*
FROM orders O INNER JOIN customers C
ON O.customer_code = C.customer_code
ORDER BY O.qty_date ASC
LIMIT 10000, 12000
Введенные в 2005-й версии функции ранжирования и в частности row_number() несколько скрасили серые будни рядовых разработчиков, но по сути проблему так и не решили. Дело в том, что конструкция LIMIT работает на уровне ядра СУБД, а функция row_number() - на пользовательском. Соответственно, скорость выполнения отличается принципиально, что особенно заметно на больших таблицах.
В данном обзоре я опишу различные методы решения задачи постраничной выборки (paging, пакетная выборка) на примере таблиц заказов и клиентов. Для тестов использовался MS SQL Server 2005 Service Pack 2 (9.00.3054.00) на рабочей станции с 2 Гб оперативной памяти (512 доступно под MS SQL) с двуядерным процессором Intel 1,8 ГГц.
Задачка
Необходимо выбрать заказы всех итальянских клиентов (код страны "IT") пачками по 100 тысяч записей в каждом. Например, пакет с 400001-й строки и по 500000-ю - это четвертый пакет в серии. Заказов, соответствующим заданному критерию, в таблице порядка 800 тысяч. Всего же в таблице содержится примерно 4 млн 300 тыс. записей. Большим такое число не назовешь, но оно уже способно неплохо загрузить наш сервер для выявления оптимальных способов решения задачи.
Описание теста
Задача теста - выявить временные показатели выполения различных способов решения нашей задачи. Каждый способ выполняется в 4-х сериях тестов:
- Серия 1: с составным ключом из символьных (nvarchar) полей, SQL Server перезапускаем только в начале серии
- Серия 2: с составным ключом из символьных (nvarchar) полей, SQL Server перезапускаем перед каждым тестом серии
- Серия 3: с простым целочисленным ключом, SQL Server перезапускаем только в начале серии
- Серия 4: с простым целочисленным ключом, SQL Server перезапускаем перед каждым тестом серии
Перезапуск сервера производиv для исключения влияния кэширования результатов предыдущих серий или отдельных тестов на последующие. После перезапуска всякий раз выполняем для "разогрева" - частичной загрузки данных в кэш и приближения к реальным условиям, следующий запрос:
SELECT count(*)
FROM orders O INNER JOIN customers C
ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
Вместо перезапуска можно также использовать команды:
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
Структура таблиц
Таблица заказов имеет простой целочисленный ключ, добавленный специально для тестов, и составной ключ из символьных полей. С небольшими упрощениями структура выглядит следующим образом.
CREATE TABLE dbo.customers (
customer_code nvarchar(15) NOT NULL,
country_code nchar(2) NOT NULL,
name nvarchar(255) NOT NULL,
street_address nvarchar(100) NULL,
city nvarchar(40) NULL,
postal_code nvarchar(15) NULL,
CONSTRAINT PK_CUSTOMERS
PRIMARY KEY NONCLUSTERED (customer_code ASC)
)
GO
CREATE INDEX IX1_COUNTRY_CODE ON dbo.customers (country_code ASC)
GO
CREATE TABLE dbo.orders (
product_code nvarchar(18) NOT NULL,
customer_code nvarchar(15) NOT NULL,
order_type nvarchar(4) NOT NULL,
qty_date datetime NOT NULL,
qty int NOT NULL,
order_id int NOT NULL,
CONSTRAINT PK_ORDERS PRIMARY KEY NONCLUSTERED(order_id ASC),
CONSTRAINT FK1_ORDERS_CUSTOMERS FOREIGN KEY(customer_code)
REFERENCES dbo.customers (customer_code)
)
GO
CREATE UNIQUE INDEX AK1_ORDERS ON orders(
product_code ASC,
customer_code ASC,
order_type ASC,
qty_date ASC)
GO
Способы решения
Для каждого метода в качестве входных параметров мы определим два входых параметра: начальное смещение (@offset - заданный номер начальной строки выборки) и размер пакета (@batch_size - требуемое количество строк в выборке, начиная с заданной). Пример объявления и инициализации параметров перед выборкой:
DECLARE @offset int, @batch_size int;
SELECT @offset = 1, @batch_size = 100;
"Классический" способ с использованием стандартного SQL
У данного способа, видимо, есть только одно достоинство: запрос выполняется практически на любой СУБД. Принцип основан на соединении таблицы на саму себя (self join), что с миллионами записей более чем накладно. На таблицах же с несколькими тысячами/десятками тысяч записей способ вполне работоспособен. Так как окончания выполнения запроса на тестовом массиве данных я не дождался, то привожу только текст запроса без внесения результатов в сводную таблицу.
SELECT O.*
FROM orders O
INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT' AND
(SELECT count(*)
FROM orders O1
INNER JOIN customers C1 ON O1.customer_code = C1.customer_code
WHERE C1.country_code = 'IT' AND
O1.product_code <= O.product_code AND
O1.customer_code <= O.customer_code AND
O1.order_type <= O.order_type AND
O1.qty_date <= O.qty_date
) BETWEEN @offset AND @offset + @batch_size - 1
ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC
В первом запросе номера строк не выводятся. Для случая с простым ключом "order_id" этот недостаток легко исправить:
SELECT num, O.*
FROM orders O
INNER JOIN
(SELECT count(*) AS num, O2.order_id
FROM orders O1
INNER JOIN customers C1 ON O1.customer_code = C1.customer_code
INNER JOIN orders O2 ON O1.order_id <= O2.order_id
INNER JOIN customers C2
ON O2.customer_code = C2.customer_code AND
C1.country_code = C2.country_code AND
C1.country_code = 'IT'
GROUP BY O2.order_id
HAVING count(*) BETWEEN @offset AND @offset + @batch_size - 1
) AS OO ON O.order_id = OO.order_id
ORDER BY OO.num ASC
Использование функции row_number()
Использование функции row_number() Пример использования функции имеется в документации к MS SQL Server (Books online), наш запрос выглядит похоже.
WITH ordered_orders AS (
SELECT O.*,
row_number() OVER(
ORDER BY O.product_code ASC,
O.customer_code ASC,
O.order_type ASC,
O.qty_date ASC
) AS row_num
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
)
SELECT *
FROM ordered_orders
WHERE row_num BETWEEN 400001 AND 500000
Использование временной таблицы
Заносим промежуточный результат (только ключевые поля) во временную таблицу с пронумерованными строками, отсекая по верхней границе, затем выбираем из нее нужный диапазон, соединяя с основной таблицей.
Не забудьте увеличить размер системной базы tempdb. Для данного примера она составила 1,5 Гбайта. В отсутствии верхнего предела для временных данных и заключается основной недостаток метода: чем больше исходная таблица и чем дальше от начального значения мы запрашиваем очередной пакет, тем больше потребуется заливать данных во временную таблицу. Конечно, дисковое пространство нынче большое и дешевое, но все таки винчестер не резиновый, да и скорость с ростом числа загружаемых во временную таблицу строк будет падать.
DECLARE @offset int, @batch_size int;
SELECT @offset = 400001, @batch_size = 100000;
CREATE TABLE #orders(
row_num int identity(1, 1) NOT NULL,
product_code nvarchar(18) NOT NULL,
customer_code nvarchar(15) NOT NULL,
order_type nvarchar(4) NOT NULL,
qty_date datetime NOT NULL
);
INSERT INTO #orders (product_code, customer_code, order_type, qty_date)
SELECT TOP (@offset + @batch_size)
O.product_code, O.customer_code, O.order_type, O.qty_date
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC;
SELECT O.*
FROM #orders T INNER JOIN orders O
ON T.product_code = O.product_code AND
T.customer_code = O.customer_code AND
T.order_type = O.order_type AND
T.qty_date = O.qty_date
WHERE T.row_num BETWEEN @offset and @offset + @batch_size - 1;
DROP TABLE #orders;
Использование инструкции TOP
Принцип основан на отсечении нужного числа записей в двух запросах с противоположным порядком следования записей. По сути здесь нет отличий от способа со временной таблицей, кроме того, что она используется неявно. Однако, сравнив результаты, мы видим, что на небольших пакетах (100 записей) SQL Server манипулирует примежуточными выборками менее эффективно, чем в способе с явным использованием временных таблиц.
DECLARE @offset int, @batch_size int;
SELECT @offset = 400001, @batch_size = 100000;
SELECT TOP (@batch_size) *
FROM
(SELECT TOP (@offset + @batch_size) O.*
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
ORDER BY O.product_code DESC, O.customer_code DESC, O.order_type DESC, O.qty_date DESC
) AS T1
ORDER BY product_code ASC, customer_code ASC, order_type ASC, qty_date ASC
Использование серверного курсора
Данный способ основан на использовании серверных курсоров и соответствующих хранимых процедур, которые на момент написания статьи не были документированы, но к настоящему времени этот недостаток полностью исправлен: Cursor Stored Procedures (Transact-SQL).
DECLARE @handle int, @rows int;
EXEC sp_cursoropen
@handle OUT,
'SELECT O.* FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = ''IT''
ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC',
1, -- Keyset-driven cursor
1, -- Read-only
@rows OUT SELECT @rows; -- Contains total rows count
EXEC sp_cursorfetch
@handle,
16, -- Absolute row index
400001, -- Fetch from row
100000 -- Rows count to fetch
EXEC sp_cursorclose @handle;
Использование SET ROWCOUNT
Хотя способ использует стандартную настройку SET ROWCOUNT, но инициализация переменной в запросе, возвращающем более дной строки, его последним значением недокументирована. Во-вторых, как подтвердил эксперимент, данный метод не работает на составных ключах. Тем не менее, в случае простого ключа способ показал неплохие результаты.
DECLARE @order_id int;
SET ROWCOUNT @offset;
SELECT @order_id = O.order_id
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
ORDER BY O.order_id ASC;
SET ROWCOUNT @batch_size;
SELECT O.*
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT' AND
O.order_id >= @order_id
ORDER BY O.order_id ASC;
SET ROWCOUNT 0;
Результаты
Сводная таблица результатов выглядит следующим образом.
| Номер первой записи (смещение) | Размер пакета | Время выполнения, сек | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Row_number | Rowcount | Server cursor | Temp table | TOP | |||||||||||||||
| 1 | 2 | 3 | 4 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | ||
| 1 | 100 | 5 | 5 | 5 | 5 | 7 | 6 | 94 | 88 | 86 | 87 | 2 | 2 | 6 | 5 | 5 | 6 | 5 | 5 |
| 1000 | 100 | 24 | 29 | 24 | 30 | 26 | 51 | 36 | 90 | 34 | 87 | 1 | 3 | 24 | 58 | 25 | 32 | 24 | 32 |
| 10000 | 100 | 79 | 108 | 78 | 107 | 80 | 81 | 36 | 88 | 33 | 87 | 2 | 3 | 78 | 78 | 79 | 81 | 78 | 80 |
| 100000 | 100 | 246 | 358 | 234 | 343 | 240 | 78 | 36 | 88 | 30 | 87 | 13 | 28 | 240 | 79 | 250 | 82 | 236 | 81 |
| 200000 | 100 | 48 | 394 | 30 | 368 | 31 | 80 | 36 | 88 | 25 | 86 | 17 | 29 | 34 | 82 | 46 | 83 | 35 | 82 |
| 300000 | 100 | 47 | 405 | 20 | 379 | 21 | 78 | 32 | 88 | 24 | 87 | 21 | 13 | 25 | 80 | 49 | 84 | 24 | 82 |
| 400000 | 100 | 59 | 426 | 24 | 386 | 25 | 80 | 31 | 88 | 21 | 86 | 27 | 30 | 29 | 81 | 68 | 84 | 29 | 83 |
| 700000 | 100 | 88 | 450 | 45 | 399 | 36 | 81 | 27 | 89 | 18 | 88 | 42 | 19 | 46 | 87 | 107 | 88 | 47 | 85 |
| 400001 | 100000 | 434 | 443 | 395 | 394 | 98 | 94 | 123 | 102 | 102 | 103 | 106 | 125 | 97 | 98 | 96 | 98 | 95 | 95 |
| 500001 | 100000 | 125 | 468 | 40 | 399 | 17 | 94 | 50 | 102 | 45 | 102 | 59 | 125 | 21 | 100 | 47 | 97 | 43 | 96 |
| 600001 | 100000 | 104 | 468 | 44 | 406 | 16 | 94 | 49 | 102 | 45 | 102 | 63 | 116 | 26 | 100 | 45 | 100 | 43 | 97 |
| 700001 | 100000 | 122 | 473 | 67 | 411 | 12 | 91 | 46 | 101 | 39 | 98 | 61 | 127 | 18 | 99 | 41 | 100 | 37 | 97 |
Номера столбцов означают:
- (1) - использование составного ключа "product_code, customer_code, order_type, qty_date", перезапуск сервера перед каждой новой серией тестов
- (2) - то же что и (1), но с перезапуском сервера перед каждым новым тестом
- (3) - использование суррогатного ключа "order_id", перезапуск сервера перед каждой новой серией тестов
- (4) - то же что и (3), но с перезапуском сервера перед каждым новым тестом
Результаты в графике:
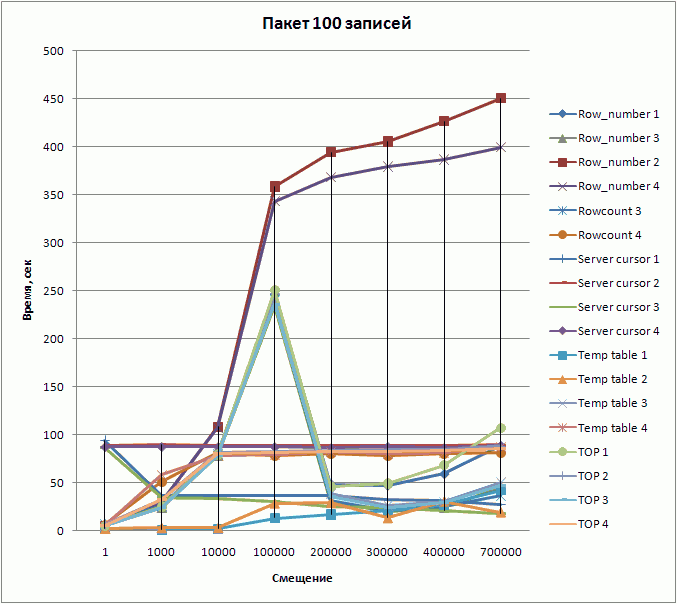
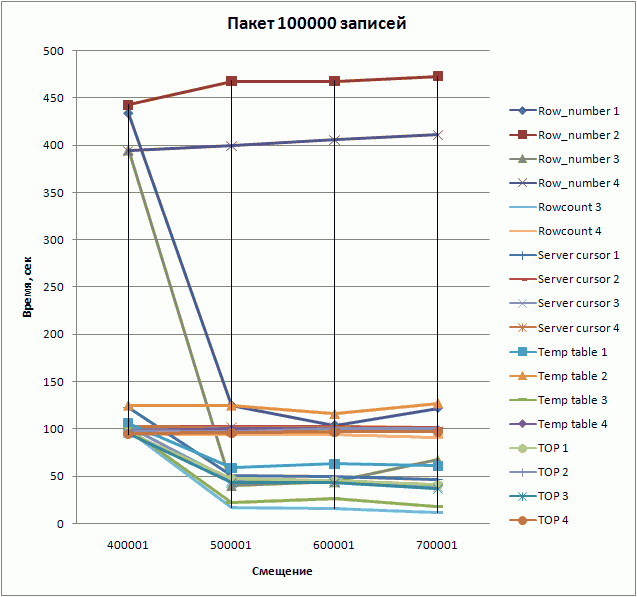
Выводы
К сожалению, появившаяся в SQL Server 2005 новая функция ранжирования row_number() показала в целом плохие результаты в тестах по сравнению с другими методами. Наиболее быстрым оказался метод с установкой ROWCOUNT, но неприменим на составных ключах. У остальных способов есть свои достоинства и недостатки, их и необходимо учесть при выборе. Наиболее универсальным методом, одновременно показывающим приемлемую скорость выборки, является использование серверного курсора: он использует ваш исходный запрос в чистом виде без необходимости добавлять к нему условий ограничения диапазона выборки, что является очень важным при работе с возвращающими результат хранимыми функциями и процедурами или проекциями (view). Например, использование функции в способе с TOP зачастую приводит к удвоению времени выборки. И, будем надеяться, что в новых версиях разработчики Microsoft все-таки реализуют на уровне ядра конструкцию LIMIT.