Архитектура документо-ориентированной информационной системы
Акжан Абдулин, 2004, сайт автора
Введение
В данной статье я постараюсь предложить некую архитектуру корпоративной информационной системы, пригодной для решения широкого спектра задач.
Большинство из начинающих разработчиков информационных систем допускают на этапах определения требований, проектирования и реализации системы одни и те же ошибки. Фактически наиболее часто встречаются такие ошибки, как:
- По существующей информации в базе данных невозможно однозначно определить состояние системы в прошлом. Это приводит к проблеме "поиска виновника";
- Откладывается решение задачи "множественности вхождений" одной сущности реального мира в базу данных. Это приводит к проблемам учёта.
- Первичные ключи изначально не определяются как уникальные в пределах всей информационной системы, включая филиалы. Это приводит к проблемам репликации.
- Используется проприетарный транспорт для взаимодействия звеньев информационной системы, что приводит к повышению TCO, проблемам с расширением функциональности системы;
- Разработка средних и больших систем ведётся по аналогии с разработкой малых систем (формозакидательство), что приводит к невозможности довести проект до рабочего состояния;
- Не принимается мер по минимизации трафика между звеньями системы, что приводит к низкой масштабируемости системы.
Естественно, наша архитектура должна предоставить солидное решение для любого крупного предприятия, начиная от базы данных через среднее звено до презентационного слоя. Мы постараемся решить большинство общих задач, стоящих перед ядром информационной системы.
Мы примем в качестве базовой платформы для этих статей:
- Microsoft SQL Server 2000 в качестве РСУБД;
- Microsoft C#.NET 2003/.NET Framework/Enterprise Services в качестве инструмента реализации среднего звена;
- ADO.NET в качестве транспорта "среднее звено - база данных";
- Borland Delphi 7 в качестве средства реализации "толстого" клиента;
- COM+/XML в качестве транспорта "среднее звено - толстый клиент";
- CA ERwin в качестве средства моделирования базы данных.
Я не хотел бы касаться здесь факторов, повлиявших на выбор именно такой платформы. С одной стороны, часть из этих факторов ярко проявится при дальнейшем изложении материала, с другой стороны, большинство предложенных здесь "зёрен" инвариантны по отношению к используемым инструментам.
Внутренние стандарты именования
- Объекты базы данных именуются согласно принадлежности к предметной области и внутренним правилам именования предметной области. Пример -
docDocument; - Столбцы именуются в стиле
TestCasing; - Поля объектов в C# именуются в стиле
_testCasing; - Поля объектов в Object Pascal именуются в стиле
FTestCasing; - Функции, методы, константы, C#-классы именуются в стиле
TestCasing; - Классы Object Pascal именуются в стиле
TTestCasing; - Интерфейсы именуются в стиле
ITestCasing; - Локальные переменные именуются в стиле
testCasing.
Основные постулаты
В качестве основных постулатов здоровой ИС мы примем таковые:
Неизменяемые сущности
Все "сущности" и "объекты" системы, определяемые в процессе проектирования, являются неизменяемыми (immutable). В то же время список "объектов", которыми владеет данная "сущность", может пополняться. Для каждой "сущности" определен атрибут "дата создания".
Унификация типов данных
- Все "сущности" в пределах системы строго определяются своим идентификатором (суррогатным ключом). Данное требование не распространяется на "объекты", которые зависят от "сущности" ("объекты" могут определяться "сущностью" и своим внутренним состоянием). За идентификатор в нашем случае примем UNIQUEID.
- Периоды (диапазоны) определяются в сущностях с помощью атрибутов (xxxBegin, xxxEnd) типа дата/время, причем значение атрибута xxxBegin входит в диапазон, а значение атрибута xxxEnd - нет. Значение атрибута xxxBegin всегда меньше или равно значению атрибута xxxEnd.
- Для даты/времени определены понятия "начало времен" и "конец времен". Никакая дата/время не может выйти за пределы данного диапазона.
Историчность состояния
Мы можем восстановить состояние нашей информационной системы на любой момент времени. Следовательно, запрещается модификация и удаление любых данных, созданных за пределами текущей транзакции. Историчность обеспечивается без использования идиомы "журнал". Сессия определяется как авторизованный сеанс работы пользователя системы. Любая информация в системе может указать на сессию, в рамках которой она была добавлена в систему. Любое действие в системе выполняется после проверки соответствующих ограничений системы безопасности.
Здесь и далее будет использоваться понятие "актуальность". Любая информация в системе имеет смысл для какого-то периода и является в этом периоде актуальной. Та информация, которая имеет смысл для настоящего момента времени, определяется нами как "актуальная".
Разнородная система
Мы могли бы использовать некий в разной степени унифицированный подход, который при некотором усложнении системы позволил бы смотреть на любой хранимый объект в системе единообразно. Тем не менее, я посчитал необходимым построить различные части системы с использованием различных архитектурных моделей. Это диктуется различными факторами.
Производительность
Производительность каждой подсистемы будет более высокой, если архитектурная модель будет оптимизирована под задачи данной подсистемы. Так, подсистема безопасности и подсистема машины проводок выполнены наиболее лаконично, так как используются крайне интенсивно.
Адекватность
Различные сущности в системе требуют скорее дифференцированного, чем единого к ним подхода. Так, "документы" по своей сути полностью отличны от "действий" и "активностей". Естественно, эти различия станут более ясны при дальнейшем изложении материала. Количество архитектурных моделей я свёл к минимуму, так как они определяются базовыми свойствами моделируемых объектов.
Модель документов
Часть информации, определяемой в системе, подпадает под определение "документа". В частности, практически все справочники и документы, определяемые при проектировании системы, лучше всего реализовать с помощью документной модели.
Типизация
Думаю, этот аспект не представляет затруднений. Каждый "документ" имеет строго определённый "тип документа". Допускается только единичное наследование типа. Типы документов выстроены в единую строгую иерархию типов.
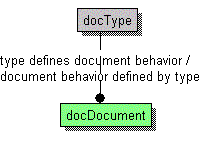
При этом я негативно отношусь к множественному наследованию и возможности мутации документов, поэтому тип документа строго определяется в самом "документе". Если Вы предпочитаете иметь возможность мутаций, то "тип документа" должен принадлежать состоянию "документа". Кроме того, имеет смысл ограничить возможность мутаций иерархией наследования типов.
Версионность и актуальность
Документ как таковой способен изменять своё состояние. Соответственно, нам нужен механизм для сохранения его состояния. Изменение состояния документа может быть либо "актуализацией документа", которая определяет состояние документа для данного периода, либо "обновлением документа", которое определяет (возможно, новую) версию состояния документа для данного периода.
Типичный вариант "актуализации документа" - внесение изменений в "документ" "Российский паспорт" при замене старого российского паспорта на новый российский паспорт. При этом номер паспорта является величиной, переменной во времени, и имеет разные значения для различных периодов.
Типичный вариант "обновления документа" - внесение поправок в описание "товара". При этом все документы, оформленные до внесения поправок в описание товара, используют старое описание товара, что обеспечивает повторяемость результатов отчётности.
Для реализации "машины состояний" мы разносим "документ" и его состояние в разные сущности. Фактически каждое изменение "документа" просто означает создание новой "версии состояния" документа. "Версия состояния" документа определяется датой/временем её создания и "периодом актуальности версии". Наиболее поздняя "версия состояния", охватывающая своим "периодом актуальности" текущий момент, является "современной версией актуального состояния".
Как видите, две различные задачи решаются использованием одного механизма.
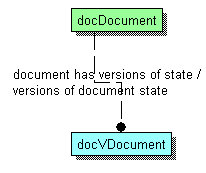
Обратите внимание, что "версия состояния объекта" является также неизменяемым объектом. Каждая новая версия совершенно независима от предыдущей версии документа. Хороший критерий правильной архитектуры: если предположить полное разрушение любой другой версии состояния документа, то это не должно никак повлиять на данную версию состояния документа.
Отобразить на клиенте историю документа можно с помощью DHTML-вставки наподобие данной:
| 23.05.2003 | [АннаК] изменила состояние документа для периода с 01.04.2003 до конца времён. Актуально с 01.04.2003 до конца времён. [Просмотреть изменения] [Проинформировать] [Отменить] |
| 23.05.2003 | [СветаС] занесла документ в папку [К исполнению] с 23.05.2003 до конца времён под именем "Приказ №4/23". Актуально с 23.05.2003 до конца времён. [Просмотреть изменения] [Проинформировать] [Отменить] |
| 02.05.2003 | [ИванБ] создал документ, определив состояние документа с 01.04.2003 до конца времён. [Просмотреть изменения] [Проинформировать] [Отменить] |
Актуализация и версионность логики
Каждому типу документов соответствует своя логика их обработки (полная аналогия с принципами объектно-ориентированного подхода). Но мы должны учитывать тот факт, что логика также имеет свойство изменяться, поэтому нам необходимо реализовать механизм актуализации и версионности логики.
Естественно, это приводит нас к мысли о формировании документов типа "Логика". В частности, документы этого типа можно ассоциировать с различными типами объектов, получая необходимые естественность и гибкость использования.
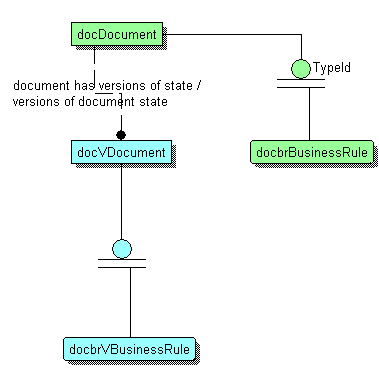
Это позволит нам быть уверенным, что для "старой" бизнес-сущности можно произвести откат и накат действий актуальным для оной сущности способом, и в то же время позволит исправлять бизнес-логику для сущностей любого периода.
Иерархичность и поимённость
Документы и иные объекты в системе имеют свойство выстраиваться в иерархичные или сетевые структуры. Для реализации таких структур мы вводим в систему понятие "папки". Необходимо отметить, что "папка" сама по себе является "документом", что означает реализацию механизма актуальности и версионности для содержимого папки.
Содержимое папки - набор ссылок на другие "документы" системы. Таким образом, мы получаем возможность создания сложных сетевых структур (N:M). Типичной сетевой структурой обладает обычный классификатор товаров.
Естественно, для системы предопределяется некий "корень" системы, являющийся "папкой". Большая часть "папок" системы будет организована в единую "сеть документов" на базе данного "корня". Во многих системах документы обладают атрибутом "имя" или "описание" документа. Я считаю данный "атрибут" крайне вредным. Вместо этого мы вводим необязательный атрибут "метка" для каждой ссылки на "документ", уникальный в пределах "версии содержимого папки". Таким образом, можно также определить понятие "пути к документу".
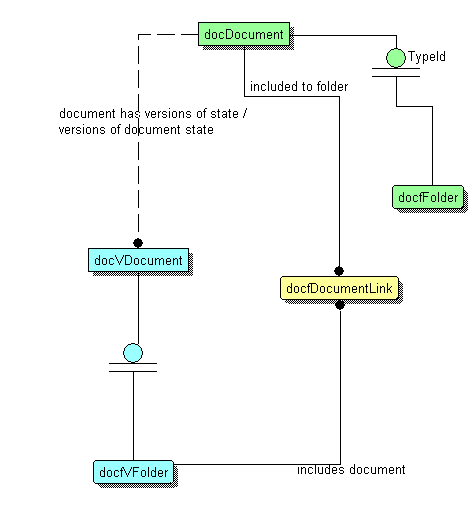
Можно заметить, что принятые допущения ограничивают возможность использования "папок" в связи с относительно низкой производительностью агрегатных операций по "сети документов". Тем не менее, данный недостаток можно исправить для отдельных фрагментов "сети документов", если заранее известно, что в этих фрагментах взаимоотношения между документами имеют строго иерархическую структуру. При разработке физической модели базы данных мы проработаем этот вопрос более плотно.
Множественность вхождений
Мы должны учитывать возможность создания различных документов, описывающих один и тот же объект реального мира. С течением времени подобные инциденты обнаруживаются, и их необходимо решать в обычном "историческом" русле.
Для решения этой проблемы мы предлагаем решение за счёт введения понятия "куста документов". "Куст документов" определяет "наиболее точный" "документ" и связанные с ним подчинённые документы. "Куст документов" сам является "папкой", и таким образом можно проследить историю переноса "документов" между "кустами". Это необходимо, в частности, для отслеживания ошибок пользователя.
Например, в типичном классификаторе товаров, в разделе "комплектующие, видеокарты" можно встретить два наименования фактически одного типа видеокарты. При этом часть сущностей уже ссылаются на одно наименование, а часть - на другое. Простое объединение наименований (merging) недопустимо, так как в таком случае теряется возможность возврата к предыдущему состоянию.
Необходимость введения понятия "куста" в основу модели не вызывает сомнений ввиду распространённости проблемы. Именно поэтому лучше реализовать всю логику "кустов" лишь один раз для всей системы. Необходимо отметить, что "кусты" сами по себе не входят в иерархию "сети документов".
Авторство
Создатель "документа" является "автором документа". В то же время создатель новой "версии состояния" является "редактором документа". Для реализации механизма авторства используется понятие "Пользователь", косвенная ссылка на который и определяет авторство.
На самом деле мы используем прямую ссылку на сессию, в рамках которой и был создан или изменён данный документ. А сессия в свою очередь указывает на пользователя и другие данные авторизации. Тем не менее, в своей системе Вы можете предпочесть хранить прямую ссылку на пользователя, чтобы не реплицировать между серверами информацию о сессиях. Но я считаю более верным хранить ссылки на точную информацию. Необходимо также отметить, что "документы" типа "Пользователь" и объекты типа "Сессия" используются также в механизме безопасности.